由于spark不存在元数据管理模块,为了能方便地通过sql操作hdfs数据,我们可以通过借助hive的元数据管理模块实现。对于hive来说,核心组件包含两个:
- sql优化翻译器,翻译sql到mapreduce并提交到yarn执行
- metastore,元数据管理中心
hive执行sql命令架构图
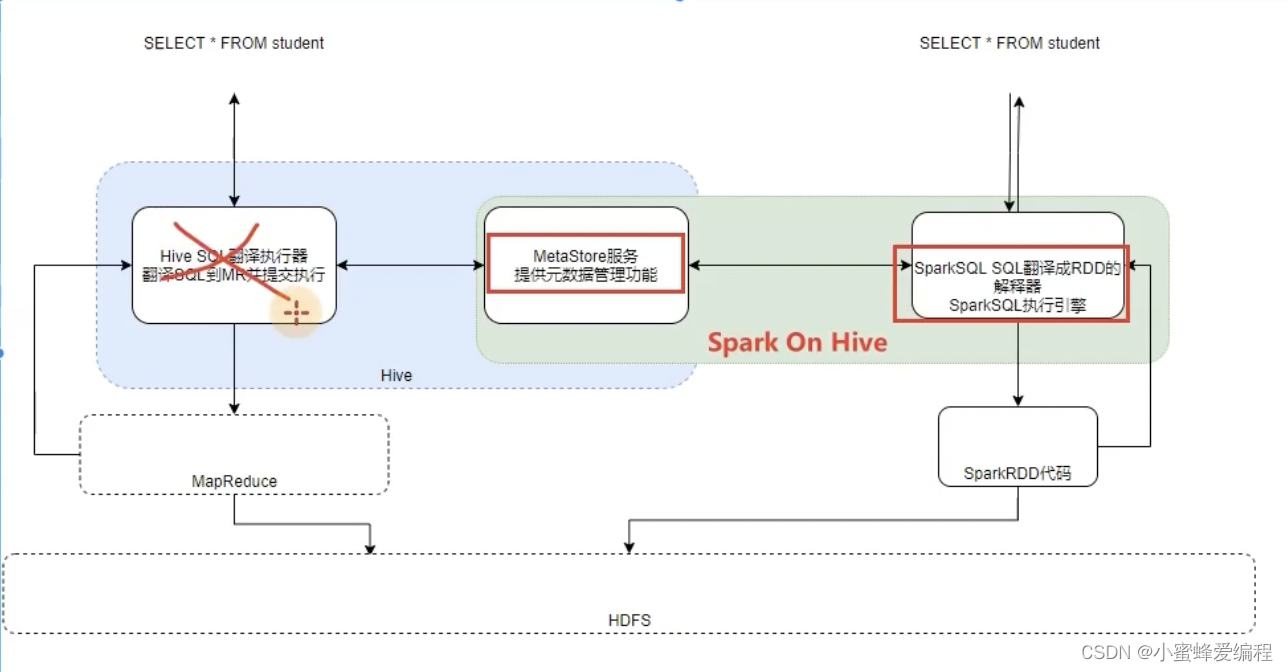
我们先来介绍下hive怎么去执行一个sql命令的,我们在提交一个sql语句后,首先会经由hive sql翻译器翻译sql到MR并提交到Yarn,但sql语句中的表字段、要选择哪个表,表放在什么地方,是需要去询问metastore服务的,metastore服务返回查询必须的的表信息,sql语句翻译成mr任务并提交到yarn上执行,mr任务从hdfs中拿到所需数据再返回。

spark on hive原理
了解hive的基本原理后,再来看spark on hive,也就是借助了hive的metastore服务,来获取表位置,然后spark sql解释器将sql翻译成rdd代码执行。也即集成hive的metastore服务即可。
对于Spark来说,自身是一个执行引擎
但是Spark自己没有元数据管理功能,当我们执行:
SELECTFROM person WHERE age>10的时候,Spark完全有能力将SQL变成RDD提交
但是问题是,Personl的数据在哪?Person有哪些字段?字段啥类型?Spark完全不知道了
不知道这些东西,如何翻译RDD运行.
在SparkSQL代码中可以写SQL那是因为,表是来自DataFrame注册的.
DataFrame中有数据,有字段,有类型,足够Spark用来翻译RDD用.
如果以不写代码的角度来看,SELECTFROM person WHERE age>10 spark无法翻译,因为没有元数据
配置spark on hive
配置spark的元数据为hive,只要保证spark能连接上hive的metastore即可。需要保证两点:
(1)hive的metastore服务正常运行;
(2)spark需要知道metastore的ip端口
配置步骤一
我们只需要在spark的conf目录中,创建hive-site.xml,然后配置以下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl"href="configuration.xsl"?>
<configuration><!--告知Spark创建表存到哪里-一><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.metastore.local</name><value>false</value></property><!-一告知Spark Hive的MetaStore在哪--><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property>
</configuration>
上面的thrift://node1:9083替换成自己的metastore服务地址,
/user/hive/warehouse替换成自己的元数据管理仓库路径即可
配置步骤二
将mysqlE的驱动jar包放入sparkl的jars目录,驱动jar包可自行网上去找
因为要连接元数据,会有部分功能连接到mysql/库,需要mysql驱动包
配置步骤三
确保Hive配置了MetaStore相关的服务
检查hive配置文件目录内的:hive-site.xml
确保有如下配置:
<configuration><property><name>hive.metastore.uris</name><value>thrift://node1:9083</value></property>
</configuration>
配置好之后就可以直接通过spark-sql工具创建表和操作表了,如果我们在hive中执行表操作,走的是map-reduce,而在spark-sql中操作则走的rdd,这是有细微区别的地方,翻译的操作不同,但元数据市一致的,但对开发者来说都一样,都是直接通过sql操作。同样,也可以在代码里面进行连接hive操作:
coding:utf8
import ..
if __name__ == '__main__':#O.构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\config("spark.sql.shuffle.partitions",2).\config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse").\config("hive.metastore.uris","thrift://node3:9083").\enableHiveSupport().\getorCreate()sc = spark.sparkContextspark.sql("SELECT * FROM student").show()
可以看到,我们上面不用创建任何临时视图,但可以直接操作student表