Hudi,这个近年来备受瞩目的数据存储解决方案,无疑是大数据领域的一颗耀眼新星。其凭借出色的性能和稳定性,以及对于数据湖场景的深度适配,赢得了众多企业和开发者的青睐。然而,正如任何一项新兴技术,Hudi在生产环境的落地过程中也暴露出了不少问题,亟待我们共同解决。尽管Hudi在数据处理速度、数据一致性以及查询效率等方面表现优异,但在实际应用中,其稳定性和可靠性仍面临挑战。在生产环境中,数据规模庞大且变化频繁,Hudi需要能够稳定地处理各种复杂场景,但目前来看,其在高并发、大数据量下的表现并不尽如人意。此外,Hudi的生态系统还不够完善,与其他大数据组件的集成度有待提高,这也给生产环境的部署和维护带来了不便。除了技术层面的问题,Hudi在生产落地过程中还面临着诸多非技术性的挑战。例如,企业对于新技术的接受程度、团队的技术水平、以及数据治理的规范程度等,都会影响到Hudi的落地效果。此外,由于Hudi相对较新,相关的文档和社区支持还不够完善,这也增加了企业在使用过程中的学习成本和风险。
本文针对Hudi在生产上常见的SQL Join场景下的衍生问题进行讨论,详见下文。
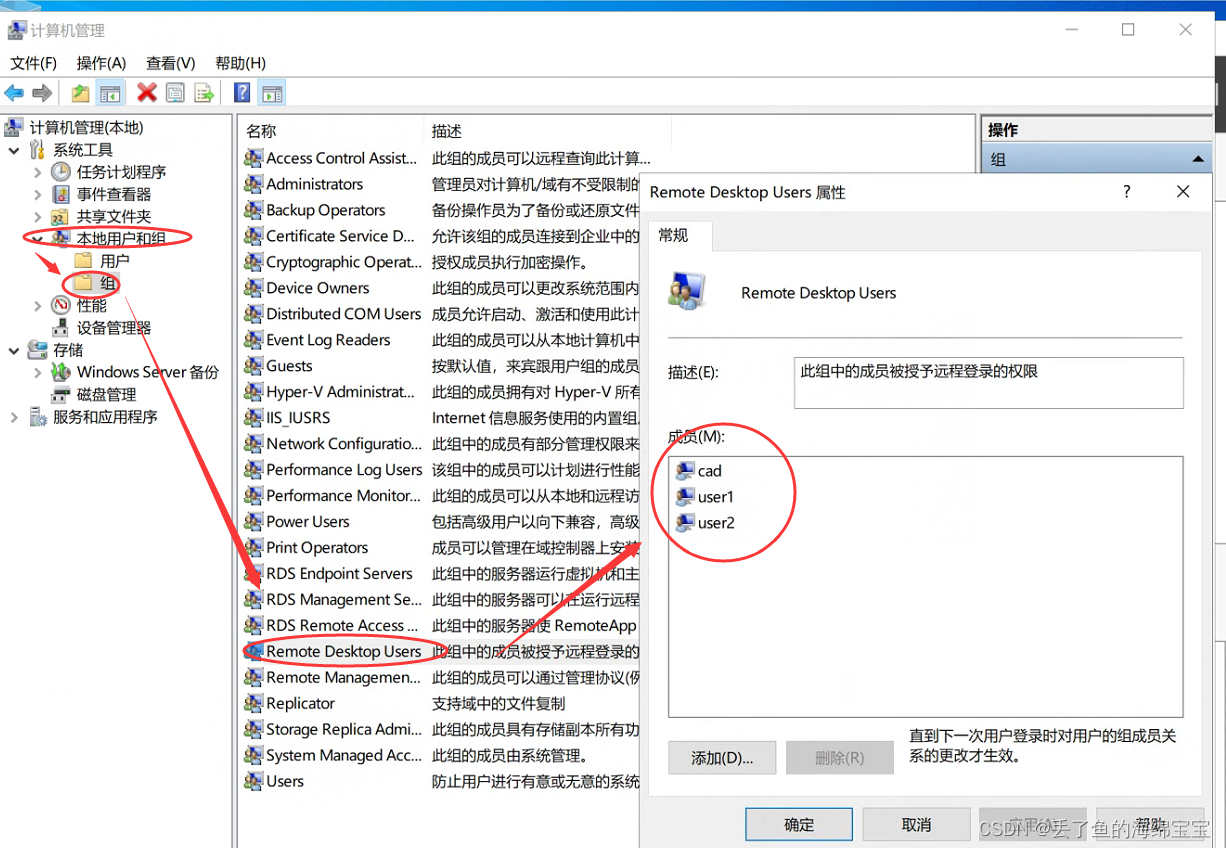
一 FlinkSQL基于Hudi维表Join场景缺陷问题分析
下面是示例代码,这段代码存在数据质量问题:
-- Hudi订单事实表
create table hudi.dwd_ord_order_info_dd(order_id bigint,product_id bigint,order_amount double,order_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dwd_ord_order_info_dd','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'order_id','hoodie.datasource.write.precombine.field' = 'order_time',......
);
-- Hudi产品维表
create table hudi.dim_product(product_id bigint,product_name string,category string,create_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dim_product','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'product_id','hoodie.datasource.write.precombine.field' = 'create_time',......
);
insert into hudi.dwd_ord_order_info_dd select ...;
insert into hudi.dim_product select ...;
-- 维表Join SQL示例(以下SQL会存在数据质量问题)
set table.exec.state.ttl = 8192s;
insert into hudi.dws_ord_order_info_dd
select *
from hudi.dwd_ord_order_info_dd t1
left join hudi.dim_product t2 on t1.product_id = t2.product_id
;上边示例中的sql表示实时订单数据流(hudi.dwd_ord_order_info_dd)关联商品维表的功能,用来补全宽表商品属性(hudi.dim_product)数据。这段SQL在实际生产环境中执行会出现数据丢失的问题,从而导致数据质量不合格。那么问题出现在哪里呢?
-
维表数据只能保存TTL时间范围内变更数据记录有效,而订单流产生交易的商品很可能是去年上架销售商品,在商品state中已经没有该商品记录信息,从而导致关联商品信息失效;
-
如果不设置TTL,那么订单流和商品流都要保存启动全量历史数据状态,这么大的状态对于内存压力巨大,如果商品维表巨大,且周期较长,那么商品维表也无法保留全部历史数据;
这里问题主要原因是订单数据事件时间和对应商品事件时间差异比较大导致的问题。
二 FlinkSQL基于Hudi维表Join场景缺陷解决方案
在章节1中我们分析了代码可能存在的问题原因,那么怎么解决呢?对于FlinkSQL来说,关联维表最好的方式是通过Lookup Join方式关联外部最新维度数据。
1 方案一
针对商品表在hbase创建商品维表,同时装载历史数据,然后通过流写入hudi维表外同时写入Hbase一份数据。伪代码如下:
为什么要创建hbase维表?
hudi表的数据文件从hdfs上看也是普通的parquet或者log格式,这种格式存储数据本质上来说对于批量分析比较友好,但对于向单行数据的快速扫描性能比较低。这一点是由存储结构造成的。
hbase表结构对于单行rowkey访问友好,但对于批处理不友好;
基于上面两点,我们只能选择在存储层通过存储两份不同格式的数据来解决批处理和单行访问之间差异的问题。
-- Hudi订单事实表
create table hudi.dwd_ord_order_info_dd(order_id bigint,product_id bigint,order_amount double,order_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dwd_ord_order_info_dd','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'order_id','hoodie.datasource.write.precombine.field' = 'order_time',......
);
-- Hudi产品维表
create table hudi.dim_product(product_id bigint,product_name string,category string,create_time timestamp(3),dt string
) partitioned by(dt)
with ('connector'='hudi','path' ='hdfs://hadoop:8020/dw/dim_product','table.type'='MERGE_ON_READ','hoodie.datasource.write.recordkey.field' = 'product_id','hoodie.datasource.write.precombine.field' = 'create_time',......
);
-- Hbase产品维表
create table hbase.dim_product(product_id bigint,product_name string,category string,create_time string,dt string
) partitioned by(dt)
with ('connector'='hbase',......
);
insert into hudi.dwd_ord_order_info_dd select ...;
create view tmp_product as ...;
insert into hudi.dim_product select * from tmp_product;
insert into hbase.dim_product select * from tmp_product;
set table.exec.state.ttl = 8192s;
insert into hudi.dws_ord_order_info_dd
select *
from hudi.dwd_ord_order_info_dd t1
left join hudi.dim_product t2 on t1.product_id = t2.product_id
left join hbase.dim_product for system_time as of t1.order_time t3 on t1.product_id = t3.product_id
;通过订单流数据同时关联hudi.dim_product和以Lookup Join方式关联相同的hbase.dim_product表方式可以解决维度延迟和历史数据关联问题,很好解决由于维度数据状态不全导致数据质量问题。
这种方式有以下两个缺点:
-
存储层面: 维表数据要存储两份数据(hudi本身存储一份全量数据,hbase也需要存储一份全量数据)。
-
ETL层面: ETL代码要多维护一份维度数据写入hbase的关系,对于代码整洁不友好。
2 方案二
这个方案侧重于在存储层解决SQL Join问题,但有个前提,不同子SQL都需要有相同的主键设置才可用,同样,这种方案也涉及源码改造,主要技术点在于Hudi payload的源码改造,具体的实现这里不介绍。
3 方案三
三 总结
在生产上遇到这种SQL 维表Join场景问题,可以采用方案一进行处理,如果团队技术比较强大,那么可以考虑方案二落地,方案三非技术大牛坐镇,不建议改造。这里对方案二三不做详细介绍,待后续更新,敬请关注。