文章目录
- 前言
- 一、线性回归
- 1.知识点
- (1)解析解
- (2)泛化
- (3)随机梯度下降
- (4)python列表推导
- (5)全连接层
- 二、线性回归的从零开始实现
- 1.知识点
- (1)scatter()
- (2)random.shuffle()
- (3)yield()
- 2.练习
- (2)假设试图为电压和电流的关系建立一个模型。自动微分可以用来学习模型的参数吗?
- (4)计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
- (5)为什么在squared_loss函数中需要使用reshape函数?
- (6)尝试使用不同的学习率,观察损失函数值下降的快慢。
- (7)如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
- 三、线性回归的简洁实现
- 1.知识点
- (1)data.TensorDataset()
- (2)data.DataLoader()
- (3)iter()和next()
- (4)Sequential()
- (5)下划线_: 原地操作
- 2.练习
- (1)如果将小批量的总损失替换为小批量损失的平均值,需要如何更改学习率?
- 四、softmax回归
- 1.知识点
- (1)独热编码
- 五、图像分类数据集
- 1.知识点
- (1)subplots()
- (2)zip()
- (3)enumerate()
- (4)imshow()
- (2)练习
- 1.减少batch_size(如减少到1)是否会影响读取性能?
- 六、softmax回归的从零开始实现
- 1.知识点
- (1)交叉熵
- (2)isinstance
- (3)eval() 评估模式
- (4)numel()
- (5)with torch.no_grad()
- (6)lambda()
- (7)hasattr
- (8)cla()
- (9)assert()
- 2.练习
- (1、2、3)自定义softmax函数和交叉熵损失函数的问题的解决方案
- (4)返回概率最大的分类标签总是最优解吗?例如,医疗诊断场景下可以这样做吗?
- (5)假设我们使用softmax回归来预测下一个单词,可选取的单词数目过多可能会带来哪些问题?
前言
这篇博客主要记录了学习第三章过程中,个人不了解的地方,以及学习这些知识点搜集的资料,以便后续复习查看。
因此,此博客只含有部分个人新学的知识点,而不会将所有知识点整理总结。
同时,知识点部分也只是简单地了解了概念,以此辅助学习,而没有深入内核。
下方为电子版书籍网页,其中代码可复制到jupyternotebook,直接运行,提高学习效率
《动手学深度学习电子版书籍》
一、线性回归
1.知识点
(1)解析解
解析解与数值解

(2)泛化
深入理解泛化
优化(optimization)是指调节模型以在训练数据上得到最佳性能(即机器学习中的学习),而泛化(generalization)是指训练好的模型在前所未见的数据上的性能好坏。
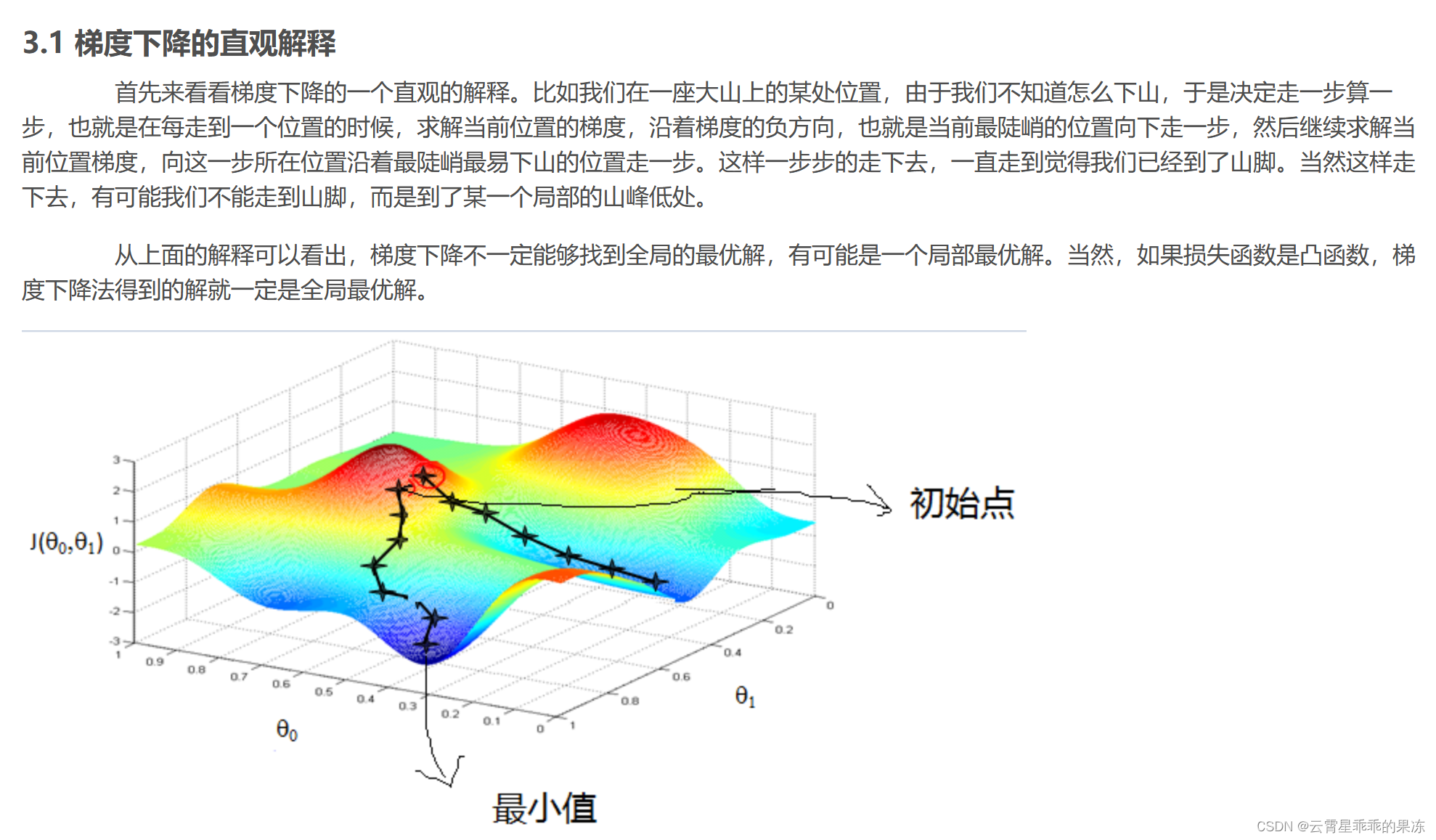
(3)随机梯度下降
随机梯度下降详解
(4)python列表推导
【技能树共建】Python 列表推导式
(5)全连接层
全连接层详解
对于线性回归,每个输入都与每个输出相连, 我们将这种变换 称为全连接层(fully-connected layer)或称为稠密层


在这一节末尾,我很喜欢下面这段话,记录一下下。
“当然,许多这样的单元可以通过正确连接和正确的学习算法拼凑在一起, 从而产生的行为会比单独一个神经元所产生的行为更有趣、更复杂, 这种想法归功于我们对真实生物神经系统的研究。
当今大多数深度学习的研究几乎没有直接从神经科学中获得灵感。 我们援引斯图尔特·罗素和彼得·诺维格在他们的经典人工智能教科书 Artificial Intelligence:A Modern Approach (Russell and Norvig, 2016) 中所说的:虽然飞机可能受到鸟类的启发,但几个世纪以来,鸟类学并不是航空创新的主要驱动力。 同样地,如今在深度学习中的灵感同样或更多地来自数学、统计学和计算机科学。”
二、线性回归的从零开始实现
1.知识点
(1)scatter()
这篇博客较为详细,可以系统学习scatter,如果只是想简单理解,可以看下文
scatter() 函数在 Matplotlib 中可以接受多个参数,以便用户能够自定义散点图的样式、颜色、大小等。
一些常用的参数:
s:指定散点的大小,可以是一个数值或一个数组,用于设置每个点的大小。
c:指定散点的颜色,可以是一个颜色名称(如 ‘red’、‘blue’)或一个颜色序列,用于设置每个点的颜色。
marker:指定散点的形状,可以是一个字符(如 ‘o’ 表示圆形、‘s’ 表示方形)或一个符号(如 ‘^’ 表示三角形、‘*’ 表示星号)。
alpha:指定散点的透明度,取值范围为 0 到 1,0 表示完全透明,1 表示不透明。
label:指定散点的标签,用于生成图例。
例子:


(2)random.shuffle()
作用:打乱数据集顺序
【Python基础】random.shuffle()的用法
(3)yield()
python中yield的用法详解——最简单,最清晰的解释
yield 是 Python 中的一个关键字,通常用于生成器函数中。生成器函数是一种特殊的函数,它可以在迭代过程中暂停并返回一个中间结果,然后在需要时再继续执行。yield 的作用是将函数的执行结果返回给调用者,并且保留了函数的当前状态,以便下次调用时可以从之前的状态继续执行。当在一个函数中使用 yield 时,这个函数就成为了一个生成器函数。
2.练习
(注:部分答案由AI给出)
(2)假设试图为电压和电流的关系建立一个模型。自动微分可以用来学习模型的参数吗?
自动微分可以用来学习电压和电流关系模型的参数。在机器学习中,自动微分技术通常被用于训练模型参数,使得模型能够更好地拟合数据并学习输入和输出之间的关系。
具体来说,在建立电压和电流关系模型时,可以定义一个参数化的模型函数,例如:
def model(voltage, params):current = some_function_of(voltage, params)return current
然后,利用自动微分工具(如 PyTorch 或 TensorFlow)来计算模型输出与真实观测值之间的损失,并通过反向传播算法来更新模型参数,使得模型预测的电流与真实电流更加接近。
自动微分通过计算损失函数对模型参数的梯度,从而指导参数更新方向,使得模型能够逐渐优化和学习到电压和电流之间的关系。这样,自动微分为学习模型参数提供了一种高效的方式,无需手动推导梯度或者编写复杂的优化算法。
(4)计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
问题
计算量大: 计算二阶导数通常比计算一阶导数更加复杂和耗时,因为需要考虑更多的交叉导数项。
数值稳定性: 在计算二阶导数时,数值稳定性可能成为一个问题,特别是当函数具有复杂的形式或者存在数值不稳定的情况时,如除以接近零的数或指数函数等。
高阶导数消失: 在某些情况下,高阶导数可能会消失,导致二阶导数的计算结果不准确或者丢失了一些信息。
计算效率低: 由于计算二阶导数通常需要更多的计算量和存储空间,可能会导致计算效率变低。
解决方法
使用自动微分工具: 使用现有的自动微分工具(如 PyTorch 或 TensorFlow)来计算高阶导数,这些工具能够有效地管理计算过程并提高计算效率。
数值稳定性处理: 在计算过程中注意数值稳定性,避免出现数值不稳定的操作,可以通过数值稳定的计算技巧来减少误差的累积。
截断高阶导数: 在实际应用中,有时可以截断高阶导数的计算,只计算到某个特定阶数的导数,以减少计算复杂度和提高效率。
优化算法选择: 对于特定的优化问题,可以根据问题特点选择合适的优化算法,有些算法可能不需要显式地计算二阶导数就能够取得很好的效果。
(5)为什么在squared_loss函数中需要使用reshape函数?
在 squared_loss 函数中使用 reshape 函数的目的是确保 y 和 y_hat 的形状一致,以便进行减法和平方操作。
在深度学习中,经常会遇到需要对张量进行形状匹配的情况。如果 y 和 y_hat 的形状不一致,直接进行减法操作可能会导致维度不匹配的错误。因此,为了保证运算能够进行,需要将 y 调整为与 y_hat 相同的形状。
具体来说,假设 y_hat 的形状是 (batch_size, 1),而 y 的形状是 (batch_size,),即 y 是一个一维张量。在这种情况下,我们需要使用 reshape 函数将 y 转换为与 y_hat 相同的形状,即 (batch_size, 1),以便进行减法和平方操作。

(6)尝试使用不同的学习率,观察损失函数值下降的快慢。




(7)如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
我设置的数据总数为8,batch_size数为10,运行结果如下:

可以看到,虽然设置batch_size为10,但是由于数据只有8个,所以只会输出8个
当最后一个批次的样本数量少于批量大小时,batch_indices 的索引范围会超出实际的样本索引范围,这可能导致索引越界错误。为了解决这个问题,可以在代码中进行处理,例如:
在计算 batch_indices 时,确保不超过样本总数,避免索引越界。
在处理最后一个批次时,可以选择忽略剩余的样本、补齐到批量大小或者采取其他策略,如下:
for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)]) # 确保不超过样本总数if len(batch_indices) < batch_size and len(batch_indices) > 0:# 可以添加处理最后一个批次的代码,比如补齐样本、忽略剩余样本或者其他操作# 这里只是简单地打印出不完整的批次print("Incomplete batch:")yield features[batch_indices], labels[batch_indices]
三、线性回归的简洁实现
1.知识点
(1)data.TensorDataset()
data.TensorDataset是PyTorch中用于包装张量数据的类,通常用于构建数据集和对应的标签集。它可以将数据张量和标签张量作为输入,并将它们封装成一个数据集对象,以便于进行后续的数据处理、批量读取等操作。
import torch
from torch.utils.data import TensorDataset, DataLoader# 假设有训练数据 data 和对应的标签 label
data = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
label = torch.tensor([0, 1])# 使用 TensorDataset 封装数据和标签
dataset = TensorDataset(data, label)# 构建 DataLoader 进行数据加载
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
(2)data.DataLoader()
data.DataLoader 是 PyTorch 中用于数据加载的工具,它可以实现对数据集的批量读取、打乱顺序、并行加载等功能。通常情况下,我们会将封装好的数据集(比如 TensorDataset)传入 DataLoader 中,以便于进行批量处理和训练神经网络模型。
import torch
from torch.utils.data import TensorDataset, DataLoader# 假设有训练数据 data 和对应的标签 label
data = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
label = torch.tensor([0, 1])# 使用 TensorDataset 封装数据和标签
dataset = TensorDataset(data, label)# 构建 DataLoader 进行数据加载
batch_size = 2
# shuffle 是在使用 DataLoader 加载数据时的一个参数,用于指定是否对数据进行打乱顺序。
# 当shuffle设置为 True 时,DataLoader 会在每个 epoch(训练周期)开始前将数据集打乱顺序
# 这样可以使得每个 epoch 中模型看到的数据顺序都是不同的,有助于增加模型的泛化能力。
shuffle = True
num_workers = 2 # 并行加载的线程数
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers)# 遍历 DataLoader 并输出每个 batch 的数据和标签
for batch_data, batch_label in dataloader:print("Batch data:", batch_data)print("Batch label:", batch_label)# 在这里可以进行模型训练等操作
运行结果:

(3)iter()和next()
在 Python 中,iter() 是一个内置函数,用于将可迭代对象转换为迭代器。迭代器是一种能够逐个返回元素的对象,而可迭代对象是一种能够被迭代器遍历的对象。
使用 iter() 函数可以将可迭代对象转换为迭代器。一旦转换完成,我们就可以使用 next() 函数从迭代器中逐个获取元素。当迭代器没有更多元素时,会抛出 StopIteration 异常。
下面是一个简单的示例,展示了如何使用 iter() 和 next():
my_list = [1, 2, 3, 4, 5] # 可迭代对象my_iter = iter(my_list) # 将列表转换为迭代器print(next(my_iter)) # 输出:1
print(next(my_iter)) # 输出:2
print(next(my_iter)) # 输出:3
在上面的示例中,我们首先创建了一个列表 my_list,它是一个可迭代对象。然后,我们使用 iter() 函数将 my_list 转换为迭代器 my_iter。接着,通过连续调用 next() 函数,我们可以逐个获取迭代器中的元素。
需要注意的是,一旦迭代器中没有更多元素,再次调用 next() 函数就会引发 StopIteration 异常,因此需要在使用时进行适当的异常处理。
(4)Sequential()
nn.Sequential 是 PyTorch 中的一个模型容器,用于以顺序的方式组织多个神经网络模块。它允许我们按照顺序将这些模块串联起来,构建一个更复杂的神经网络模型。
使用 nn.Sequential,我们可以通过简单地传入一系列的模块来定义我们的模型结构,而无需手动编写前向传播函数。
下面展示了如何使用 nn.Sequential 定义一个简单的全连接神经网络模型:
import torch
import torch.nn as nnmodel = nn.Sequential(nn.Linear(10, 20), # 第一个全连接层,输入大小为10,输出大小为20nn.ReLU(), # ReLU 激活函数nn.Linear(20, 30), # 第二个全连接层,输入大小为20,输出大小为30nn.ReLU() # ReLU 激活函数
)
(5)下划线_: 原地操作
在 Python 中,下划线 _ 通常用作一个临时变量或占位符。它的具体含义取决于上下文。
在 PyTorch 中,方法名称以 _ 结尾的形式,例如 normal_() 和 fill_(),表示它们是原地(in-place)操作。原地操作是指在不创建新对象的情况下,直接修改原始对象的值。它们会直接修改权重和偏置参数的值,而不会返回任何结果。
import torch# 创建一个张量
x = torch.tensor([1.0, 2.0, 3.0])# 使用原地操作对张量进行修改
x.add_(1.0) # 原地加法操作,等同于 x = x + 1.0print(x) # 输出修改后的张量
2.练习
(1)如果将小批量的总损失替换为小批量损失的平均值,需要如何更改学习率?
当将小批量的总损失替换为小批量损失的平均值时,通常需要相应地调整学习率。这是因为平均损失和总损失具有不同的尺度。
假设使用的是随机梯度下降(SGD)优化算法,并且在每个小批量样本上计算了损失,然后求取这些损失的平均值作为小批量的总损失。在这种情况下,可以将学习率除以小批量大小来调整学习率。
具体来说,如果原始学习率为 lr,小批量大小为 batch_size,则在每次更新模型参数时,将学习率设置为 lr / batch_size。这样可以保持学习率的相对大小不变,同时适应了小批量损失的平均值。
四、softmax回归
1.知识点
(1)独热编码
机器学习中使用的独热编码
五、图像分类数据集
1.知识点
(1)subplots()
plt: subplot()、subplots()详解及返回对象figure、axes的理解
(2)zip()
zip()函数的用法
(3)enumerate()
python enumerate用法总结
(4)imshow()
Matplotlib imshow() 方法 菜鸟教程
(2)练习
1.减少batch_size(如减少到1)是否会影响读取性能?
AI给的答案:
减少 batch_size 可能会影响读取性能,具体取决于数据集的大小和存储方式、硬件设备以及数据读取的方式。
数据集大小和存储方式:如果数据集较小且存储在较慢的存储介质上(例如硬盘而非固态硬盘),较小的 batch_size 可能会增加数据读取的开销,因为在每个训练步骤中都需要从磁盘加载更多的数据。
硬件设备:在使用 GPU 进行训练时,较小的 batch_size 可能无法充分利用 GPU 的并行计算能力,导致 GPU 的利用率下降,从而影响性能。另一方面,如果系统内存有限,减少 batch_size 可能会减少内存占用,从而提高整体性能。
数据读取方式:如果使用了数据预加载或者数据预处理技术,较小的 batch_size 可能会增加数据加载和处理的开销,尤其是在每个训练步骤中都需要对数据进行额外的处理时。
综上所述,减少 batch_size 可能会对读取性能产生影响,但影响的具体程度取决于多个因素。在实际情况下,可以根据具体的硬件环境和数据集特点进行实验,并根据实际效果来确定最佳的 batch_size 大小。
六、softmax回归的从零开始实现
1.知识点
(1)交叉熵
交叉熵损失函数原理详解
(2)isinstance
isinstance 是 Python 的一个内置函数,用于检查一个对象是否属于指定类或类型。
语法如下:
isinstance(object, classinfo)
object:要检查的对象。
classinfo:类名、类型或者由它们组成的元组。
isinstance 函数会返回一个布尔值,表示该对象是否属于指定的类或类型。
例如:
x = 5
print(isinstance(x, int)) # 输出 True,因为 x 是整数类型
print(isinstance(x, str)) # 输出 False,因为 x 不是字符串类型
(3)eval() 评估模式
快速学pytorch之评估模式:model.eval()
在 PyTorch 中,通过调用 eval() 方法可以将模型切换为评估模式,这通常用于在推理阶段使用模型而不进行梯度计算。评估模式下,模型中的一些特定层(如 Dropout)可能会表现出不同的行为,以保证模型的输出稳定性。
(4)numel()
numel 是 PyTorch 中的一个函数,用于返回张量中元素的总数。具体来说,numel 返回的是张量的维度大小的乘积,即张量中包含的元素个数。
(5)with torch.no_grad()
with torch.no_grad() 是 PyTorch 中的上下文管理器,用于在该上下文中禁用梯度计算。在这个上下文中,PyTorch 不会跟踪张量的梯度,这样可以节省内存并提高运行效率。通常情况下,with torch.no_grad(): 被用于推断阶段,即在不需要计算梯度的情况下进行模型的推理。
(6)lambda()
python——lambda函数
(7)hasattr
【python】hasattr( )的用法
hasattr 是 Python 中的一个内置函数,用于检查对象是否具有指定的属性。
语法如下:
hasattr(object, attribute)
object 是要检查的对象。
attribute 是要检查的属性名。
(8)cla()
cla() 是 Matplotlib 中 Axes 对象的一个方法,用于清除当前 Axes 对象中的内容,即清空当前绘图区域,准备绘制新的内容。调用 cla() 方法可以清除之前绘制的图形,以便在同一个 Axes 对象上重新绘制新的图形或数据。
(9)assert()
python中assert的用法(简洁明了)
Python中的assert用法
在 Python 中,assert 语句用于检查一个条件是否为真,如果条件为假,则会引发 AssertionError 异常。assert 语句的一般形式如下:
assert condition, message
condition 是需要被检查的条件,如果条件为假(False),则会触发 AssertionError。
message 是可选的,用于在 AssertionError 中指定出错时的信息。
当程序执行到 assert 语句时,会首先对 condition 进行求值,如果为真(True),则程序继续执行;如果为假(False),则会引发 AssertionError。这种断言通常用于在开发和测试阶段对程序执行的结果进行检查,帮助发现潜在的问题或错误。
2.练习
(注:以下答案全部由AI生成)
(1、2、3)自定义softmax函数和交叉熵损失函数的问题的解决方案

Softmax 函数的问题:
当输入向量中的元素较大时,指数函数可能导致数值溢出或数值稳定性问题。
计算结果可能存在数值不稳定性,并且可能影响模型的训练和预测结果。
交叉熵损失函数的问题:
对数函数在定义域内为负无穷到正无穷,如果输入包含非常接近或等于零的值,可能导致计算出现无穷大或无法收敛的情况。
针对上述问题,可以采取以下解决方案:
Softmax 函数的数值稳定处理:
在计算 softmax 函数时,可以对输入向量进行归一化处理,即减去输入向量中的最大值,以减小指数函数的值,提高数值稳定性。
可以使用 softmax 函数的 log-sum-exp 表示来计算,以避免指数函数操作带来的数值问题。
交叉熵损失函数的数值稳定处理:
在计算交叉熵损失函数时,可以对预测概率值进行限制,避免输入值接近或等于零。
可以在计算交叉熵损失函数时,对预测概率值进行平滑处理,如添加一个极小值,以避免对数函数计算出现异常情况。
通过以上处理方式,可以提高数值稳定性,避免数值计算问题,确保模型训练和预测的准确性和稳定性。
(4)返回概率最大的分类标签总是最优解吗?例如,医疗诊断场景下可以这样做吗?
在大多数情况下,返回概率最大的分类标签并不总是最优解,特别是在医疗诊断等领域。虽然概率最大的分类标签可能是模型认为最有可能的类别,但在实际应用中需要综合考虑其他因素。
在医疗诊断场景下,确诊结果可能受到多个因素的影响,包括但不限于:
误诊风险:仅仅依赖于概率最大的分类标签可能忽略了其他可能性,增加了误诊的风险。
医疗专家知识:医疗诊断往往需要结合医疗专家的知识和经验,综合考虑病人的病史、症状等信息。
不确定性:医疗诊断可能存在一定的不确定性,患者的病情可能具有多样性和复杂性,单一概率最大的分类标签可能无法完全覆盖所有情况。
因此,在医疗诊断等重要场景下,通常会采取以下策略来提高诊断准确性和可靠性:
多因素综合考虑:除了模型输出的概率最大分类标签外,还需考虑其他因素,如医疗专家意见、辅助检查结果等。
不确定性估计:对模型输出的概率值进行不确定性估计,提供患者可能属于不同类别的概率范围,而非仅仅依赖于单一分类标签。
风险评估:综合考虑误诊风险,采取相应的风险管理措施,如进一步检查或复核。
综合考虑各种因素,可以帮助提高医疗诊断的准确性和可靠性,避免仅仅依赖于概率最大的分类标签而造成误诊的情况。
(5)假设我们使用softmax回归来预测下一个单词,可选取的单词数目过多可能会带来哪些问题?
当使用 softmax 回归来预测下一个单词时,如果可选取的单词数目过多,可能会导致以下问题:
计算复杂度高:
随着可选单词数目的增加,softmax 函数的计算复杂度会呈指数级增长,需要计算所有可能单词的概率分布。这将导致训练时间和推理时间大幅增加。
内存消耗大:
需要存储所有可能单词的概率分布,如果可选取的单词数目很大,将占用大量内存空间。
稀疏性问题:
当可选取的单词数目过多时,训练数据中每个样本对应的标签向量会变得非常稀疏,这会使模型难以学习有效的表示,影响模型的泛化能力。
标签噪声:
过多的可选单词可能导致训练数据中存在大量的标签噪声,使模型难以准确学习每个单词的概率分布。
为了解决上述问题,可以采取以下策略:
降低类别数量:
可以通过合并相似的单词或者仅选择出现频率较高的单词作为候选,来降低可选取的单词数目。
层次 softmax:
使用层次 softmax(hierarchical softmax)来减少 softmax 函数的计算复杂度,通过构建树形结构对单词进行分类,减少概率计算的时间复杂度。
负采样:
使用负采样(negative sampling)代替 softmax 来训练模型,通过随机采样出一小部分负例来估计概率,从而降低计算复杂度。
通过以上策略,可以在保证模型效果的同时,降低计算复杂度和内存消耗,提高模型的训练和推理效率。
![每日一题 --- 977. 有序数组的平方[力扣][Go]](https://img-blog.csdnimg.cn/direct/cc73369402bb40f0ba52de6a070fb35a.png)