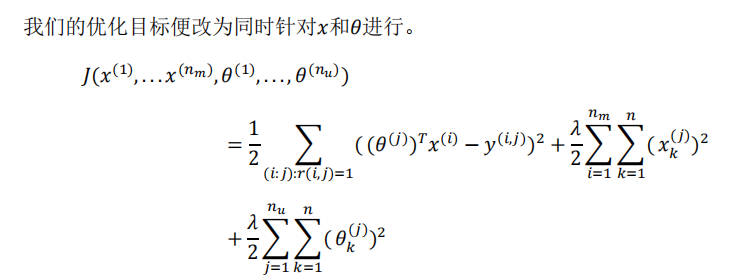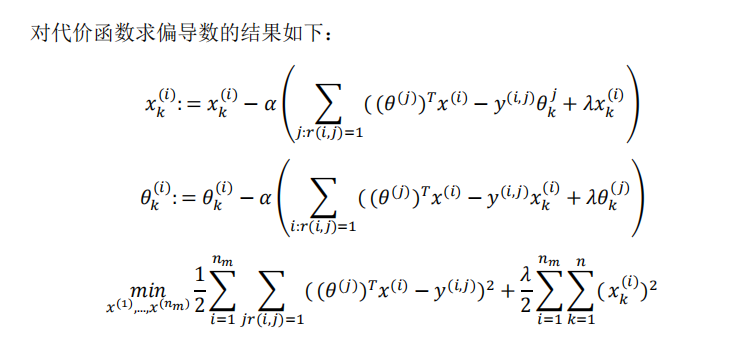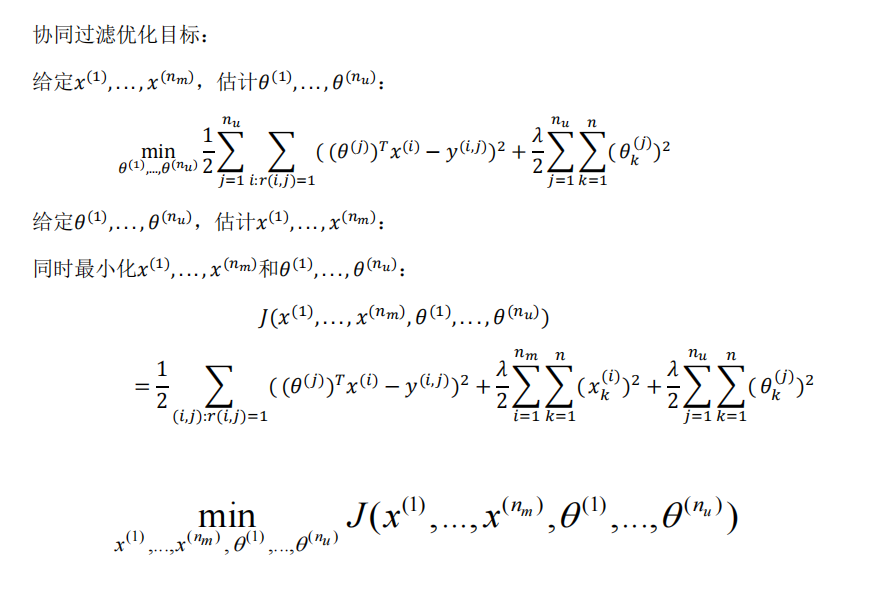文章目录
- 定义问题
- 基于内容的推荐系统
- 协同过滤
定义问题
我们从一个例子开始定义推荐系统的问题。
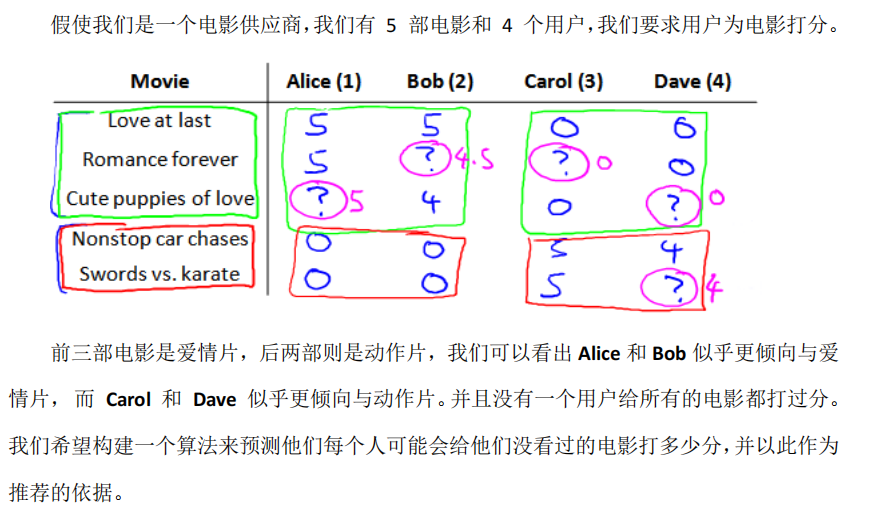
下面引入一些标记:

基于内容的推荐系统
在一个基于内容的推荐系统算法中,我们假设对于我们希望推荐的东西有一些数据,这些数据是有关这些东西的特征。
在我们的例子中,我们可以假设每部电影都有两个特征,如𝑥1代表电影的浪漫程度,𝑥2代表电影的动作程度。
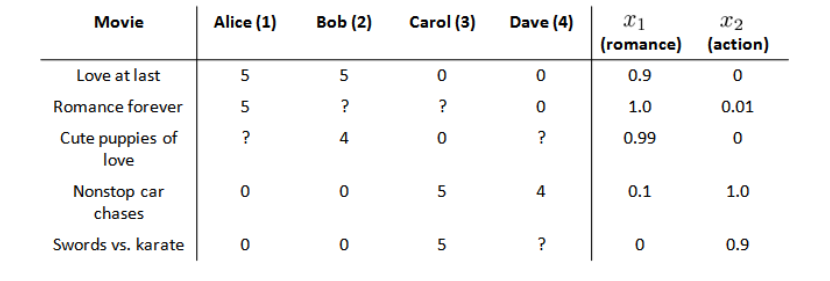


这里是相似度实现
import numpy as npclass ContentBasedRecommender:def __init__(self, movies):self.movies = moviesself.movie_features = {} # 物品特征字典,键为电影 ID,值为特征向量def fit(self):# 为每个电影创建特征向量for movie_id, movie_info in self.movies.items():features = np.zeros(len(self.movies)) # 假设特征维度为电影总数for genre in movie_info['genres']:features[self.movies[genre]['index']] = 1 # 根据电影类型设置特征值self.movie_features[movie_id] = featuresdef recommend(self, movie_id, num_recommendations=5):# 计算给定电影的特征向量movie_features = self.movie_features[movie_id]# 计算与给定电影特征最相似的电影similarities = {}for other_movie_id, other_features in self.movie_features.items():similarity = np.dot(movie_features, other_features) / (np.linalg.norm(movie_features) * np.linalg.norm(other_features))similarities[other_movie_id] = similarity# 根据相似度排序并返回推荐列表sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True)recommendations = []for movie_id, similarity in sorted_similarities[:num_recommendations]:recommendations.append((movie_id, self.movies[movie_id]['title']))return recommendations# 示例电影数据
movies = {1: {'title': 'The Shawshank Redemption', 'genres': ['Drama']},2: {'title': 'The Godfather', 'genres': ['Crime', 'Drama']},3: {'title': 'The Dark Knight', 'genres': ['Action', 'Crime', 'Drama']},# 其他电影...
}# 初始化推荐系统并拟合数据
recommender = ContentBasedRecommender(movies)
recommender.fit()# 示例推荐
movie_id = 1 # 假设用户正在查看电影 The Shawshank Redemption
recommendations = recommender.recommend(movie_id)
print("Recommendations for {}: {}".format(movies[movie_id]['title'], recommendations))代价函数梯度下降法
import numpy as npclass ContentBasedRecommender:def __init__(self, movies, num_features, learning_rate=0.01, num_iterations=1000):self.movies = moviesself.num_movies = len(movies)self.num_features = num_featuresself.learning_rate = learning_rateself.num_iterations = num_iterationsself.movie_features = np.random.randn(self.num_movies, self.num_features) # 物品特征矩阵self.errors = []def fit(self, ratings):for _ in range(self.num_iterations):# 计算预测评分predicted_ratings = np.dot(self.movie_features, self.movie_features.T)# 计算误差error = np.sum((predicted_ratings - ratings) ** 2)self.errors.append(error)# 计算梯度并更新特征矩阵gradient = 2 * np.dot((predicted_ratings - ratings), self.movie_features)self.movie_features -= self.learning_rate * gradientdef predict(self, user_id):return np.dot(self.movie_features, self.movie_features[user_id])# 示例电影评分数据
ratings = np.array([[5, 4, 0, 0],[0, 0, 3, 4],[5, 0, 0, 0],[0, 0, 4, 5],
])# 示例电影数据
movies = {0: {'title': 'The Shawshank Redemption'},1: {'title': 'The Godfather'},2: {'title': 'The Dark Knight'},3: {'title': 'Inception'},
}# 初始化推荐系统并拟合数据
recommender = ContentBasedRecommender(movies, num_features=2)
recommender.fit(ratings)# 预测用户评分
user_id = 0 # 假设用户 ID 为 0
predictions = recommender.predict(user_id)
print("Predicted ratings for user {}: {}".format(user_id, predictions))协同过滤
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数。相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征。
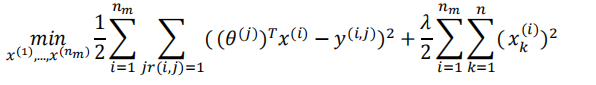
但是如果我们既没有用户的参数,也没有电影的特征,这两种方法都不可行了。协同过滤算法可以同时学习这两者。