1.SQL概述
1.1基本表(Base table)
- 实际存储在数据库中的表
- SQL中一个关系就对应一个基本表
- 基本表可以有若干个索引
- 基本表的集合组成关系模式,即全局概念模式(数据的整体逻辑结构)
1.2 存储文件
- 存储文件和相关索引组成了关系的内模式,即存储模式
- 一个基本表可跨一个或多个存储文件,一个存储文件可存放一个或多个基本表
- 一个存储文件与外存储器上的一个物理文件相对应
1.3视图(view)
- 从一个或几个基本表或其它视图导出来的表
- 视图本身并不独立存储数据,系统只保存视图的定义
- 访问视图时,系统将按照视图的定义从基本表中存取数据
- 视图是个虚表,它动态地反映基本表中的当前数据,这与数据的静态复 制不同。
- 从用户的观点出发,基本表和视图都是关系,用SQL一样访问
- 视图可以看作用户按照需要定义的外模式,即用户的局部数据逻辑结构
- 用户可以在视图上再定义视图
2.数据定义
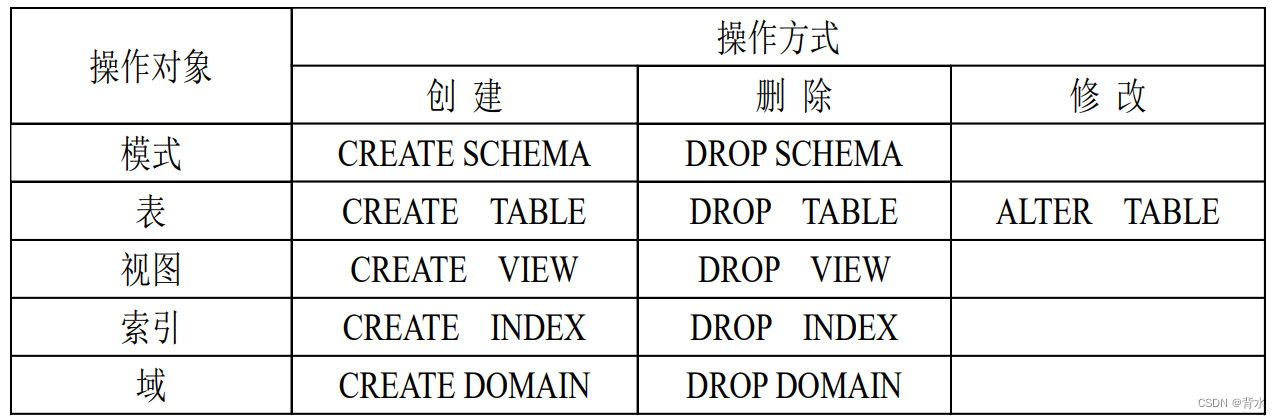
2.1数据定义语言(DDL)
对SQL模式、基本表、视图、索引的定 义和删除以及对基本表的修改和对域的定义等
2.2命名机制
现代关系数据库管理系统提供了一个层次化 的数据库对象命名机制。
- 一个关系数据库管理系统的实例(Instance) 中可以建立多个数据库
- 一个数据库中可以建立多个模式
- 一个模式下通常包括多个表、视图和索引等 数据库对象
2.3模式
2.3.1定义模式
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>
例如:CREATE SCHEMA “S-T” AUTHORIZATION WANG;
表示:为用户WANG定义一个学生-课程模式S-T
2.3.2删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
- CASCADE(级联):删除模式的同时把该模式中所有的数据库对象全部删除
- RESTRICT(限制):若该模式中定义了下属的数据库对象(如表、视图等),则拒绝该 删除语句的执行。仅当该模式中没有任何下属的对象时才能执行
2.4基本表
2.4.1定义

例:建立一个“学生”表Student,它由学号Sno、姓名 Sname、性别Ssex、年龄Sage、所在系Sdept五个属性组成。 其中学号不能为空,值是唯一的,并且姓名取值也唯一。
CREATE TABLE Sudent
(Sno CHAR(9) PRIMARY KEY,-- 列级完整性约束条件Sno是主码Sname CHAR(20) UNIQUE,-- UNIQUE约束Sname取唯一值Ssex CHAR(2),Sage SMALLINT,Sdept CHAR(20)
);常用完整性约束:
- 主码约束: PRIMARY KEY
- 唯一性约束: UNIQUE
- 非空值约束: NOT NULL
- 参照完整性约束: [FOREIGN KEY (列名)] REFERENCES <外表名>(外表列名)
例:建立一个“学生选课”表SC,它由学号Sno、课程号 Cno,修课成绩Grade组成,其中(Sno, Cno)为主码。
create table sc
(Sno char(9),Cno char(3),Grade int ,Primary Key(Sno,Cno),-- 主码有两个必须用表级完整性定义。foreign key (Sno) references student (Sno),-- 表级完整性约束条件,Sno是外码,被参照表是Studentforeign key (Cno) references Course (Cno),-- 表级完整性约束条件, Cno是外码,被参照表是Course
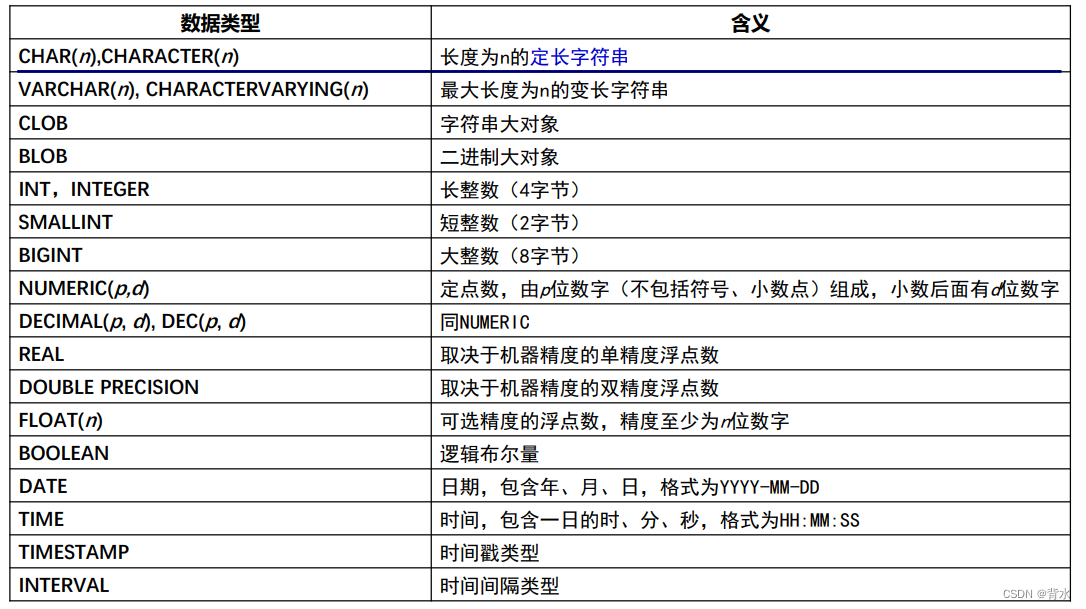
);2.4.2数据类型
2.4.3修改基本表

例:(1)向Student表增加“入学时间”列,数据类型为日期型
alter table Student ADD S_entrance DATE;
-- 不管基本表中原来是否已有数据,新增加的列一律为空值(2)将年龄的数据类型由字符型(假设原来的数据类型是字符型) 改为整数。
alter table Student alter column Sage INT;(3)增加课程名称必须取唯一值的约束条件
ALTER TABLE Course ADD UNIQUE(Cname);2.4.4索引的建立与删除

例:(1)为学生-课程数据库中的Student,Course,SC三个表建立索引。 Student表按学号升序建唯一索引,Course表按课程号升序建唯一索引, SC表按学号升序和课程号降序建唯一索引。
CREATE UNIQUE INDEX Stusno ON Student(Sno);
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);2.4.5修改索引
ALTER INDEX <旧索引名> RENAME TO <新索引名>
(1)将SC表的SCno索引名改为SCSno。
ALTER INDEX SCno RENAME TO SCSno;2.4.6删除索引
DROP INDEX <索引名>;
(1)删除Student表的Stusname索引
DROP INDEX Stusname;2.5数据字典
- 数据字典是关系数据库管理系统内部的一组系统表,它记录了数据库中所有 对象的定义信息以及一些统计信息:
- 关系模式、表、视图、索引的定义;完整性约束的定义;各类用户对数 据库的操作权限 ;统计信息等。
- 关系数据库管理系统在执行SQL的数据定义语句时,实际上就是在更新 数据字典表中的相应信息。
3.数据查询

- 根据WHERE子句的条件表达式
- 从FROM子句指定的基本表或视图中找出满足条件的元组
- 再按SELECT子句中的目标列表达式,选出元组中的属性值形成结果表
- 如果有ORDER BY子句,则结果表要根据指定按升序或降序排序
- GROUP BY子句将结果按分组,每个组产生表中的一个元组。如 果带有聚集函数的HAVING短语,则只有满足指定条件的组才予以输出。

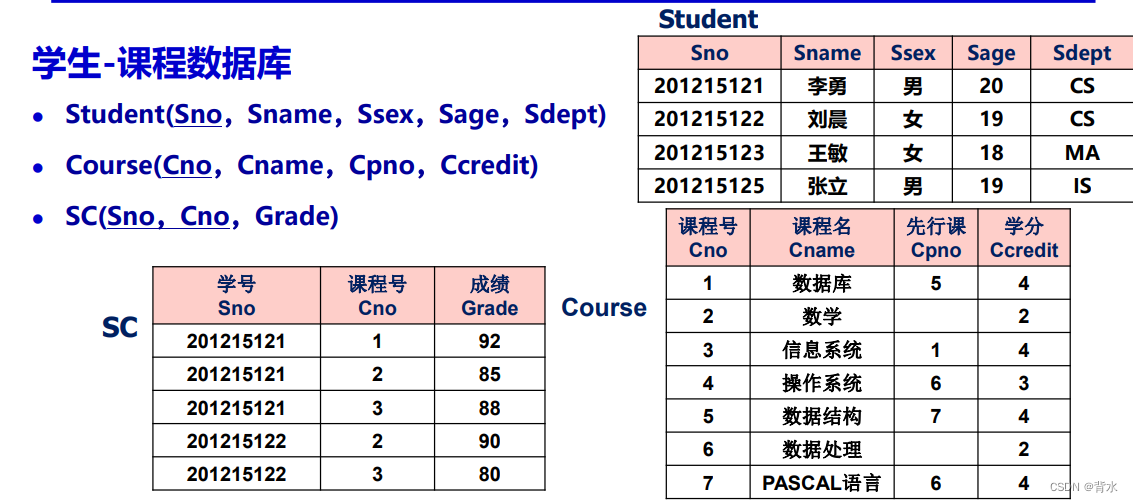
例
(1)查询全体学生的学号与姓名
SELECT Sno,Sname
FROM Student;查询全部列:在SELECT关键字后面列出所有列名、将<目标表达式>指定为 *
SELECT子句的 <目标表达式> 不仅可以为表中的属性列,也可以是表达式。
例
(1)查全体学生的姓名及其出生年份
SELECT Sname,2019-Sage /*假设当时为2019年*/
FROM Student;

(2)查询全体学生的姓名、出生年份和所在的院系,要求用小写字母表 示系名。
SELECT Sname,
'Year of Birth: '
,2019-Sage,LOWER(Sdept)
FROM Student;(3)使用列别名改变查询结果的列标题
SELECT Sname NAME,'Year of Birth:' BIRTH,
2019-Sage BIRTHDAY,LOWER(Sdept) DEPARTMENT
FROM Student;3.1选择表中的若干元组
消除取值重复的行
查询选修了课程的学生学号。
如果没有指定DISTINCT关键词,则缺省为ALL:
SELECT Sno FROM SC; 等价于:SELECT ALL Sno FROM SC;
指定DISTINCT关键词,去掉表中重复的行:
SELECT DISTINCT Sno FROM SC;
3.2查询满足条件的元组
(1)查询计算机科学系全体学生的名单。
SELECT Sname
FROM Student
WHERE Sdept=‘CS’;(2)查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < 20;(3)查询考试成绩有不及格的学生的学号。
SELECT DISTINCT Sno -- 注意DISTINCT
FROM SC
WHERE Grade<60;
3.3确定范围
谓词: BETWEEN … AND … , NOT BETWEEN … AND …
(1)查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系 别和年龄
SELECT Sname, Sdept, Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;3.4确定集合
谓词:IN<值表> , NOT IN<值表>
(1)查询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的 姓名和性别。
SELECT Sname, Ssex
FROM Student
WHERE Sdept IN (‘CS’,'MA’,'IS' );3.5字符匹配

例
(1)查询所有姓刘学生的姓名、学号和性别
SELECT Sname, Sno, Ssex
FROM Student
WHERE Sname LIKE '刘%';
(2)查询姓"欧阳"且全名为三个汉字的学生的姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳__';3.6涉及空值的查询
IS NULL 或 IS NOT NULL
“IS” 不能用 “=” 代替
例
(1)某些学生选修课程后没有参加考试,所以有选课记录,但没有 考 试成绩。查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno, Cno
FROM SC
WHERE Grade IS NULL3.7多重条件查询
逻辑运算符:AND和 OR来连接多个查询条件
AND的优先级高于OR
可以用括号改变优先级
例:
(1)查询计算机系 、年龄在20岁以下 的学生姓名
SELECT Sname
FROM Student
WHERE Sdept= 'CS' AND Sage<20;
3.8ORDER BY子句
- 可以按一个或多个属性列排序
- 升序:ASC;
- 降序:DESC;
- 缺省值为升序
例
(1)查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序 排列。
select Sno,Grade
from SC
where Cno='3'
order by Grade desc;(2)查询全体学生情况,查询结果按所在系的系号升序排列,同一系中 的学生按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept, Sage DESC;
4.聚集函数

(1)查询学生总人数。
SELECT COUNT(*)
FROM Student;(2)查询选修了课程的学生人数
select count(distinct Sno)
from SC;(3)计算1号课程的学生平均成绩。
select avg(Grade)
from SC
where Cno='1';(4)查询选修1号课程的学生最高分数
select max(grade)
from SC
where Cno='1';(5)查询学生201215012选修课程的总学分数。
select sum(Ccredit)
from SC,Course
where Sno='201215012' and SC.Cno=Course.Cno;5.GROUP BY子句
GROUP BY 子句的HAVING 短语——对每一组内的数据进行条件设定。
例如:(1)查询选修了3门及以上课程的学生学号。
select Sno
from SC
group by Sno
having count(*)>=3; -- zz或者是count(Cno)>3;过程:
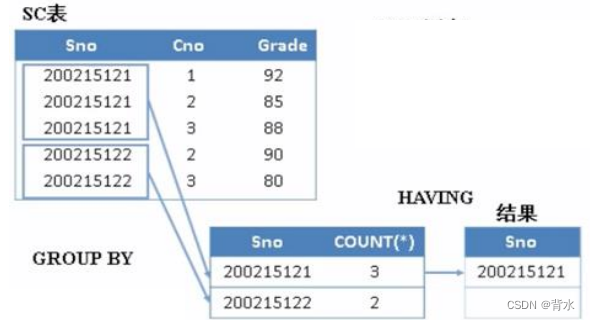
中间过程:
| Sno | Cno | Grade |
| 200215121 | 1 | 92 |
| 2 | 85 | |
| 3 | 88 | |
| 200215122 | 2 | 90 |
| 3 | 80 |
先分组,接着执行having中的语句,对Cno进行count(注意因为是按照Sno进行分组,所以Sno相当于索引了,聚集函数不会对其进行操作)。
5.1区别
GROUP BY子句分组:细化聚集函数的作用对象
- 如果未对查询结果分组,聚集函数将作用于整个查询结果
- 对查询结果分组后,聚集函数将分别作用于每个组
HAVING短语与WHERE子句的区别:
- 作用对象不同
- WHERE子句作用于基表或视图的每个记录,从中选择满足条件的元组
- HAVING短语作用于组,从中选择满足条件的组。
例(1)查询平均成绩大于等于90分的学生学号和平均成绩
select Sno,avg(Grade)
from SC
group by Sno
having avg(Grade)>=90;(2)下面有关HAVING子句,说法不正确的是(C)
A.使用HAVING子句的作用是过滤掉不满足条件的分组;
B.使用HAVING子句的同时可以使用WHERE子句;
C.使用HAVING子句的同时不能使用WHERE子句;
D.HAVING子句必须与GROUP BY 子句同时使用,不能单 独使用
(3)列出计算机系CS所有姓刘同学的信息,按学号排序
select *
from Student
where Sdept='CS' and Sname like '刘%'
order by Sno ass;(4)按系并区分男女统计各系学生人数,按人数降序排列
select Sdept,Ssex,count(Sno)
from student
group by Sdept,Ssex
order by count(sno) desc;过程:首先按照系别分组,接着系别中按照性别分组,然后选择系别、性别、人数。
6.连接查询
- 连接查询:同时涉及两个以上的表的查询
- 在 SQL中“连接”是用“连接条件”来表达的
- 连接条件或连接谓词:用来连接两个表的条件,

- 连接字段:连接谓词中的列名称,连接条件中的各连接字段类型必须是可比的,但名字不必相同
6.1等值与非等值连接查询
6.1.1等值连接
等值连接:连接运算符为 =
例(1)查询每个学生及其选修课程情况
select Student.*,SC.* -- 注意这里<表名>.*代表表中所有属性
from Student,SC
where Student.Sno=SC.Sno;6.1.2自然连接(去掉重复列)
对6.1.1中例1用自然连接完成。
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student,SC
WHERE Student.Sno = SC.Sno;因为两个表中处理Sno其他名字不同,所以可以不用加“<表名>.”
注意:一条SQL语句可以同时完成选择和连接查询
WHERE子句由连接谓词和选择谓词组成的复合条件
例(1)查询选修2号课程且成绩在90分以上的所有学生的学号和姓名。
select Student.Sno,Sname
from Student,SC
where Cno='2' and Student.Sno=SC.Sno and Grade>=90;执行过程:先从SC中挑选出Cno= '2'并且Grade>90的元组形成一个中间关系,再和Student中满足连接条件的元组进行连接得到最终的结果关系。因为DBMS会自动选择最优的,连接费事费空间,所以可以先筛选。
6.2自身连接
- 一个表与其自己进行连接
- 需要给表起别名以示区别
- 由于所有属性名都是同名属性,因此必须使用别名前缀
例:
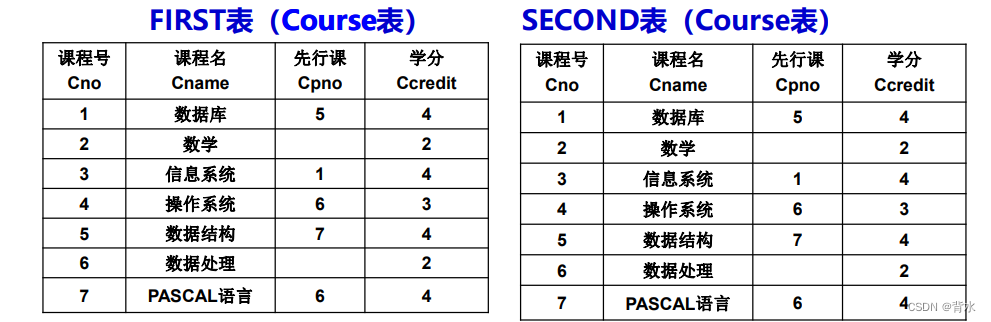
(1)查询每一门课的间接先修课(即先修课的先修课)
select first.Cno,second.Cpro
from first,second
where first.Cpro=second.Cno;6.3外连接
外连接与普通连接的区别:
- 普通连接操作只输出满足连接条件的元组
- 外连接操作,以指定表为连接主体,将主体表中不满足连接条件的元组一并输出
- 左外连接:列出左边关系中所有的元组
- 右外连接:列出右边关系中所有的元组
6.4多表连接
(1)查询每个学生的学号、姓名、选修的课程名及成绩
select Student.Sno,Sname,Cname,Grade
from Student,SC,Course
where Student.Sno=SC.Sno and Course.Cno=SC.Cno;7.嵌套查询
- 一个SELECT-FROM-WHERE语句称为一个查询块
- 将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语的 条件中的查询称为嵌套查询
SELECT Sname /*外层查询/父查询*/
FROM Student
WHERE Sno IN
( SELECT Sno /*内层查询/子查询*/
FROM SC
WHERE Cno= '2');
SQL语言允许多层嵌套查询:即一个子查询中还可以嵌套其他子查询
子查询的限制:不能使用ORDER BY子句
7.1带有IN谓词的子查询
例(1)查询与“刘晨”在同一个系学习的学生。
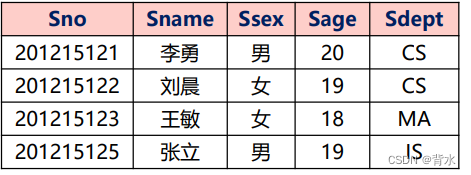
step1.确定“刘晨”所在系名
SELECT Sdept
FROM Student
WHERE Sname= '刘晨';step2.查找所有在CS系学习的学生。
select Sname
from Student
where Sdept ='CS';将第一步查询嵌入到第二步查询的条件中:
select Sname
from Student
where Sdept in(
select Sdept
from Student
where Sname='刘晨';);注:此查询为不相关子查询:子查询的查询条件不依赖于父查询。由里向外 逐层处理。
即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父 查询的查找条件。
另解:用自身连接完成
SELECT S1.Sno, S1.Sname,S1.Sdept
FROM Student S1,Student S2
WHERE S1.Sdept = S2.Sdept AND
S2.Sname = '刘晨';
例(2)查询选修了课程名为“信息系统”的学生学号和姓名。
select Sno,Sname
from Student
where Sno in(
select Sno
from SC,Course
where Course.Cno=SC.Cno and Cname='信息系统';);解法2:
SELECT Sno,Sname
FROM Student
WHERE Sno IN
(
SELECT Sno
FROM SC
WHERE Cno IN
(
SELECT Cno FROM Course
WHERE Cname=
'信息系统'
)
)解法3
SELECT Sno,Sname
FROM Student,SC,Course
WHERE Student.Sno = SC.Sno AND
SC.Cno = Course.Cno AND
Course.Cname='信息系统';7.2带有比较运算符的子查询
当能确切知道内层查询返回单值时,可用比较运算符
例(1)找出每个学生超过他选修课程平均成绩的课程号.
SELECT Sno, CnoFROM SC xWHERE Grade >= (SELECT AVG(Grade) FROM SC yWHERE y.Sno=x.Sno);注意:相关子查询,子查询的查询条件依赖于父查询
7.2.1相关子查询可能的执行过程
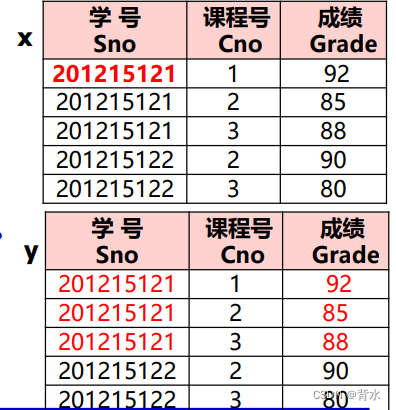
step1:从外层查询中取出SC的一个元组x,将元组x的Sno值(201215121)传送给内层查询。
SELECT AVG(Grade)
FROM SC y
WHERE y.Sno='201215121';step2:执行内层查询,得到值88(近似值), 用该值代替内层查询,得到外层查询:
SELECT Sno,Cno
FROM SC x
WHERE Grade >=88;step3:执行这个查询,得到(201215121,1)、(201215121,3)。
step4:然后外层查询取出下一个元组重复做上述①至③步骤,直到外层的SC元组全部处理完毕。
7.3嵌套查询求解方法总结
7.3.1不相关子查询
子查询的查询条件不依赖于父查询:
- 由里向外 逐层处理
- 即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父 查询的查找条件。
7.3.2相关子查询
子查询的查询条件依赖于父查询
- 首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处 理内层查询,若WHERE子句返回值为真,则取此元组放入结果表
- 然后再取外层表的下一个元组
- 重复这一过程,直至外层表全部检查完为止
7.4带有ANY(SOME)或ALL谓词的子查询
在谓词逻辑中,还有存在量词和全称量词的概念,在SQL中并没有对应的表达,统一采用“谓词” 来表达。
方法一:引入ANY和ALL谓词
- 其对象为某个查询结果
- 表示其中任意一个值或者全部值
方法二:引入EXIST谓词
- 其对象也是某个查询结果
- 但表示这个查询结果是否为空,返回真值。
7.4.1ANY和ALL

例(1)查询非计算机科学系中比计算机科学系任意某个学生年龄小的学生 姓名和年龄.
select Sname,Sage
from Student
where Sage < any(select Sagefrom Studentwhere Sdept='CS';)and Sdept <> 'CS';
执行过程:首先处理子查询,找出CS系中所有学 生的年龄,构成一个集合1,处理父查询,找所有不是CS系且年龄 小于any(集合1)的元素。(其实也可以是直接<min(....))
例(2)查询非计算机科学系中比计算机科学系所有学生年龄都小的学生 姓名及年龄
方法一是将例1的any改成all。
方法二:
SELECT Sname,Sage
FROM Student
WHERE Sage <
(SELECT MIN(Sage)
FROM Student
WHERE Sdept= ' CS ')
AND Sdept <>' CS ';
7.5带有EXISTS谓词的子查询
EXISTS谓词 存在量词
- 带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或 逻辑假值“false“.
- 若内层查询结果非空,则外层的WHERE子句返回真值
- 若内层查询结果为空,则外层的WHERE子句返回假值
- 由EXISTS引出的子查询,其目标列表达式通常都用 *
- 因为带EXISTS的子查询只返回真或假值,给出列名无实际意义
NOT EXISTS谓词
- 若内层查询结果非空,则外层的WHERE子句返回假值
- 若内层查询结果为空,则外层的WHERE子句返回真值
例(1)查询所有选修了2号课程的学生姓名。
分析:本查询涉及Student和SC关系,在Student中依次取每个元组的Sno值,用此值去检查SC表,若SC中存在这样的元组,其Sno值等于此Student.Sno值,并且其Cno= ‘2’,则取此Student.Sname送入结果表。
SELECT Sname
FROM Student
WHERE EXISTS
(SELECT *
FROM SC
WHERE Sno=Student.Sno AND Cno= ' 2 ');本题也可以用in和连接去做。
例题(2)已知S(S#,SN,AGE,SEX),S#学号,SN姓名。若要检索所有比' 王华'年龄大的学生姓名、年龄和性别,正确的SELECT语句是(A)
A:SELECT SN, AGE, SEX FROM S
WHERE AGE>(SELECT AGE FROM S
WHERE SN='王华')
B:SELECT SN,AGE,SEX FROM S
WHERE SN='王华'
C:SELECT SN,AGE,SEX FROM S
WHERE AGE>(SELECT AGE
WHERE SN='王华')
D:SELECT SN,AGE,SEX FROM S
WHERE AGE > 王华.AGE
8.数据更新
8.1插入数据
8.1.1插入元组

例(1)将一个新学生元组(学号:201215128;姓名:陈冬;性别:男; 所在系:IS;年龄:18岁)插入到Student表中。
insert into Student(Sno,Sname,Ssex,Sdept,Sage)
values('201215128','陈东','男','IS',18);注意:VALUES子句与INTO子句相对应一致
例(2)插入一条选课记录( '200215128','1 ')。
INSERT INTO SC(Sno,Cno)
VALUES ('201215128 ','1');
-- 或者
INSERT INTO SC
VALUES ('201215128 ','1',NULL);例(3)插入全部信息,INTO子句可省略列名
INSERT INTO Student
VALUES ('201215126','张成民','男’,18,'CS');8.1.2插入子查询结果

例(1)对每一个系,求学生的平均年龄,并把结果存入数据库
第一步:建表
CREATE TABLE Dept_age
( Sdept CHAR(15) /*系名*/
Avg_age SMALLINT); /*学生平均年龄*/第二步:插入数据
INSERT INTO Dept_age(Sdept,Avg_age)
SELECT Sdept,AVG(Sage)
FROM Student
GROUP BY Sdept;
8.2修改数据

8.2.1修改某一个元组的值
将学生201215121的年龄改为22岁.
UPDATE Student SET Sage=22
WHERE Sno=' 201215121 ‘;8.2.2修改多个元组的值
将所有学生的年龄增加1岁.
update Student set Sage=Sage+1;
8.2.3带子查询的修改语句
关系数据库管理系统在执行修改语句时会检查修改操作是否破坏 表上已定义的完整性规则
- 实体完整性:主码不允许修改
- 用户定义的完整性: NOT NULL约束、 UNIQUE约束、 值域约束
将计算机科学系全体学生的成绩置零.
UPDATE SC SET Grade=0
WHERE Sno IN
(SELETE Sno
FROM Student
WHERE Sdept= 'CS' );8.3删除数据

8.3.1删除某一个元组的值
删除学号为201215128的学生记录.
DELETE FROM Student
WHERE Sno= '201215128';8.3.2. 删除多个元组的值
删除所有的学生选课记录。
DELETE FROM SC;8.3.3带子查询的删除语句
删除计算机科学系所有学生的选课记录。
DELETE FROM SC
WHERE Sno IN(
SELETE Sno
FROM Student
WHERE Sdept= 'CS’
);9.视图
视图的特点:
- 虚表,是从一个或几个基本表(或视图)导出的表
- 只存放视图的定义,不存放视图对应的数据
- 基表中的数据发生变化,从视图中查询出的数据也随之改变
9.1建立视图

注意:
- 关系数据库管理系统执行CREATE VIEW语句时只是把视图定义存 入数据字典,并不执行其中的SELECT语句
- 在对视图查询时,按视图的定义从基本表中将数据查出。
例(1)建立信息系学生的视图
create view IS_Student
as
select Sno,Sname,Sage
from Student
where Sdept='IS';例(2)建立信息系学生的视图,并要求进行修改和插入操作时仍需保证该 视图只有信息系的学生 。
CREATE VIEW IS_Student AS
SELECT Sno,Sname,Sage
FROM Student
WHERE Sdept= 'IS' WITH CHECK OPTION;- WITH CHECK OPTION子句:对该视图进行插入、修改和删除操作时,RDBMS会自动 加上Sdept='IS'的条件。
- 若一个视图是从单个基本表导出的,并且只是去掉了基本表的某些行和某些 列,但保留了主码,称这类视图为行列子集视图。
- 上面的IS_Student视图就是一个行列子集视图
9.1.1基于多个基表的视图
例(1)建立信息系选修了1号课程的学生的视图(包括学号、姓名、 成绩)
create view IS_s1(Sno,Sname,Grade)
as
select Student.Sno,Sname,Grade
from Student,SC
where Sdept='IS' and Cno='1'and
Student.Sno=SC.Sno;9.1.2基于视图的视图
例(1)建立信息系选修了1号课程且成绩在90分以上的学生的视图。
CREATE VIEW IS_S2
AS
SELECT Sno,Sname,Grade
FROM IS_S1
WHERE Grade>=90;9.1.3带表达式的视图
例(1)定义一个反映学生出生年份的视图。
CREATE VIEW BT_S(Sno,Sname,Sbirth)
AS
SELECT Sno,Sname,2014-Sage
FROM Student;
9.1.4分组视图
将学生的学号及平均成绩定义为一个视图
create view S_G(Sno,Gavg)
as
select Sno,avg(Grade)
from SC
group by Sno;9.2删除视图

9.3查询视图

例(1)在信息系学生的视图中找出年龄小于20岁的学生。
SELECT Sno,Sage
FROM IS_Student
WHERE Sage<20;
视图消解转换后的查询语句为:
SELECT Sno,Sage
FROM Student
WHERE Sdept= 'IS' AND Sage<20;视图消解法的局限:有些情况下,视图消解法不能生成正确的查询。
例(2)在S_G视图中查询平均成绩在90分以上的学生学号和平均成绩
SELECT *
FROM S_G
WHERE Gavg>=90;

上面由于:聚集函数不能在where子句里面。
9.4更新视图
例(1)将信息系学生视图IS_Student中学号”201215122”的学生姓 名改为”刘辰” 。
UPDATE IS_Student
SET Sname= '刘辰'
WHERE Sno= ' 201215122 ';转换后的语句:
UPDATE Student
SET Sname= '刘辰'
WHERE Sno= ' 201215122 ' AND Sdept= 'IS';
例(2)向信息系学生视图IS_S中插入一个新的学生记录,其中学号 为”201215129”,姓名为”赵新”,年龄为20岁
INSERT
INTO IS_Student
VALUES(‘201215129’,’赵新’,20);转换为对基本表的更新:
INSERT
INTO Student(Sno,Sname,Sage,Sdept)
VALUES(‘200215129 ','赵新',20,'IS' );例(3)删除信息系学生视图IS_Student中学号为”201215129”的记录
DELETE
FROM IS_Student
WHERE Sno= ' 201215129 ';转换为对基本表的更新:
DELETE
FROM Student
WHERE Sno= ' 201215129 ' AND Sdept= 'IS';
注意:
- 更新视图的限制:一些视图是不可更新的,因为对这些视图的更新不 能唯一地有意义地转换成对相应基本表的更新
- 允许对行列子集视图进行更新
- 对其他类型视图的更新不同系统有不同限制
比如下面:
UPDATE S_G
SET Gavg=90
WHERE Sno=
'201215121';这个对视图的更新无法转换成对基本表SC的更新,因为不可能修改多个数据使平均成绩变成90分。
9.5视图的作用
- 视图能够简化用户的操作
- 当视图中数据不是直接来自基本表时,定义视图能够简化用户的操作
- 基于多张表连接形成的视图
- 基于复杂嵌套查询的视图
- 含导出属性的视图
- 当视图中数据不是直接来自基本表时,定义视图能够简化用户的操作
- 视图使用户能以多种角度看待同一数据
- 视图机制能使不同用户以不同方式看待同一数据,适应数据库共享的需要
- 视图对重构数据库提供了一定程度的逻辑独立性
- 比如:数据库重构 :学生关系Student(Sno,Sname,Ssex,Sage,Sdept),“垂直”地分成两个基本表:SX(Sno,Sname,Sage) 、SY(Sno,Ssex,Sdept)。通过建立一个视图使两个表连接在一起,形成Student(Sno,Sname,Ssex,Sage,Sdept)。
- 使用户的外模式保持不变,用户的应用程序通过视图仍然能够查找数据
- 由于对视图的更新是有条件的,因此应用程序中修改数据的语句可能仍会因 基本表结构的改变而改变——一定程度的逻辑独立性
- 视图能够对机密数据提供安全保护
- 对不同用户定义不同视图,使每个用户只能看到他有权看到的数据
- 适当的利用视图可以更清晰的表达查询