一:什么是微调(Fine-tuning)
微调(Fine-tuning)是一种在深度学习中常见的策略,特别适用于自然语言处理(NLP)、图像识别和其他机器学习任务,其中训练数据可能有限。这种方法涉及到取一个已经在大量数据集上预训练的模型,并对其进行额外的训练,以便它能够更好地执行某个特定任务。这里的关键是利用预训练模型已经学习到的丰富知识和模式,从而加速和改善新任务的学习过程。
二:微调的好处
2. 改善模型性能
3. 增强模型的泛化能力
4. 灵活性和适用性
5. 减少标注成本
-
1. 提高学习效率
- **快速收敛:**由于模型已经在大量数据上预训练,它已经学习了许多通用特征。这意味着模型在特定任务上需要的训练时间更短,因为它只需要调整其参数以适应新任务的特定要求。
- **节省时间和资源:**与从头开始训练模型相比,微调需要的计算资源和时间显著减少。这使研究者和开发者能够更快地迭代和改进他们的模型。
- **更高的准确率:**微调允许模型在特定任务上达到更高的准确率。预训练模型提供了一个强大的基础,通过针对性的训练,可以使模型在特定领域的表现超过从头开始训练的模型。
- **处理数据稀缺:**在数据稀缺的情况下,从头开始训练一个复杂的模型很难获得好的性能。微调通过利用预训练的知识,可以有效地在较小的数据集上学习,从而克服数据限制的问题。
- **泛化到新任务:**预训练模型在广泛的数据上学习,能够捕捉到丰富的特征和模式。通过微调,这些通用知识可以帮助模型更好地泛化到新的、未见过的数据或任务上。
- **适应不同领域:**即使是在与预训练数据分布大不相同的领域,微调也能通过调整模型参数来适应新领域的特点,从而提高模型在该领域的表现。
- **跨领域应用:**预训练模型和微调技术的灵活性使其可以应用于跨领域的多种任务,从文本分类、情感分析到图像识别和语音识别等。
- **定制化模型:**微调允许研究者和开发者根据他们的具体需求和数据特性调整模型,使得模型更贴合特定任务或业务需求。
- **利用无标注数据:**预训练通常在无标注或自动标注的大规模数据集上进行,减少了昂贵的人工标注成本。微调时只需少量标注数据即可实现性能提升,进一步降低了成本。
三:微调的缺点
- **过拟合风险:**在数据量较小的情况下,fine-tuning可能会导致模型对训练数据过拟合,这意味着模型在训练数据上表现良好,但是在未见过的数据上表现不佳。
- **调参复杂:**fine-tuning过程中需要调整多个超参数(如学习率、训练时长等),这可能会比较复杂且需要大量的实验来找到最优配置。
- **领域适应性问题:**如果预训练模型的数据与目标任务的数据在统计特性上有很大差异,直接fine-tuning可能会导致模型性能不佳。在这种情况下,可能需要额外的领域适应技术。
- **模型尺寸限制:**使用大型预训练模型进行fine-tuning时,模型的尺寸可能会限制其在资源受限的环境中的应用,例如在移动设备或嵌入式系统中
四:微调的常见步骤
-
**选择预训练模型:**首先,选择一个适合你任务的预训练模型。例如,对于文本相关任务,你可能会选择GPT或BERT;对于图像相关任务,则可能选择ResNet或VGG。
-
**准备任务特定数据:**虽然预训练模型已经在大型通用数据集上学习了通用特征,但你需要准备和整理特定任务的数据集来进行微调。
-
**模型调整:**这个步骤包括调整预训练模型的架构,以适应特定任务的需求。这可能涉及到修改最后几层网络、添加新的层或调整输出层以匹配任务的输出格式。
-
**微调训练:**接下来,在特定任务的数据集上继续训练(或微调)模型。这通常使用较低的学习率进行,以避免破坏模型已经学到的有用特征。
-
**评估和调整:**最后,评估微调后模型的性能,并根据需要进一步调整模型参数或训练过程。
五:微调的常见步骤
1.JSONL格式数据集
{"messages": [{ "role": "system", "content": "<放入系統訊息>" },{ "role": "user", "content": "<放入使用者的問題>" },{ "role": "assistant", "content": "<放入理想的回答>." }]
}
2.将数据集上传至官网:
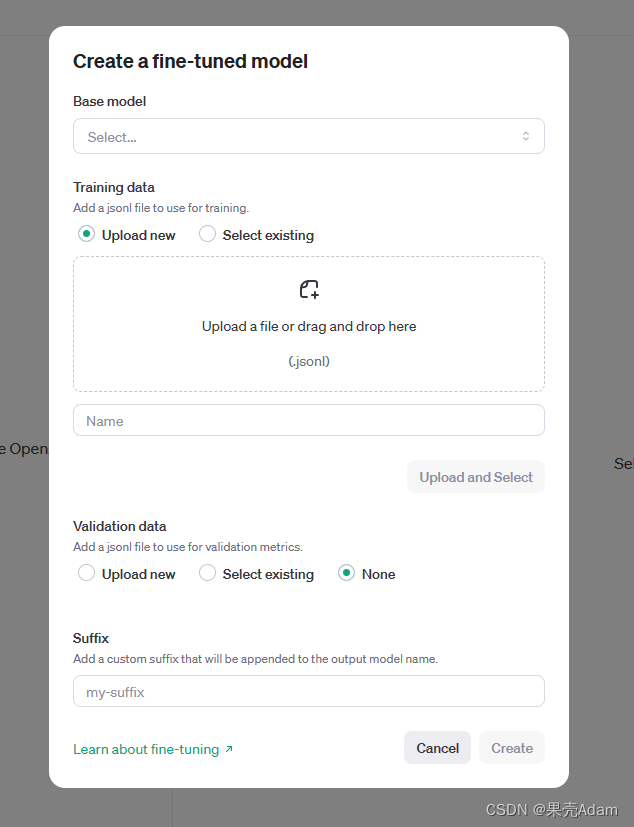
下面的Validation data指的是验证集,可选可不选。将数据集上传后会得到一个ID。
3.调用即可,注意api_key需要自行去官网申请,并且是收费的,可以查看官网的收费记录,是按照token进行收费。
from openai import OpenAI
client = OpenAI(api_key="123")# openai.api_key = "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"
fine_tuning_response = client.fine_tuning.jobs.create(# training_file=training_file_id,training_file="file-7Y29cL44qCUYKVccC3QoGbdv",# validation_file="file-TPI62L4jYrqfSRqN447484xS",model="gpt-3.5-turbo-0125",suffix="wys20240308",# hyperparameters={# "n_epochs": 4,# "batch_size": 128# }
)
job_id = fine_tuning_response.id
print(fine_tuning_response)print("获取任务ID:", job_id)
在此进行简要介绍,微调是现在很多企业都会选择的方法,既能节约成本,又能完成很复杂的任务。大模型的提出对社会带来巨大影响,有着丰富的机遇和挑战,如何把握,是每个人值得思考的点。