目录
任务调度
分布式任务调度
分布式任务调度存在的问题以及解决方案
使用SpringTask实现单体服务的任务调度
XXL-job分布式任务调度系统工作原理
XXL-job系统组成
XXL-job工作原理
使用XXL-job实现分布式任务调度
配置调度中心XXL-job
登录调度中心创建执行器和任务
在pom文件中加入XXL-job依赖
在application.yml中设置参数配置
创建配置类并交给Spring容器的Bean进行管理
创建任务代码并通过@XxlJob注解指定处理器
参考链接
任务调度
任务调度:系统为了自动完成特定任务,在约定的特定时刻去执行任务的过程。有了任务调度即可解放更多的人力由系统自动去执行任务。
常见任务调度的应用场景:
- 某电商系统需要在每天上午10点,下午3点,晚上8点发放一批优惠券。
- 某银行系统需要在信用卡到期还款日的前三天进行短信提醒。
- 某财务系统需要在每天凌晨0:10结算前一天的财务数据,统计汇总。
- 12306会根据车次的不同,而设置某几个时间点进行分批放票。
- 某网站为了实现天气实时展示,每隔5分钟就去天气服务器获取最新的实时天气信息。
分布式任务调度
分布式任务调度: 当前软件的架构已经开始向分布式架构转变,将单体结构拆分为若干服务,服务之间通过网络交互来完成业务处理。在分布式架构下,一个服务往往会部署多个实例来运行我们的业务,如果在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度。
分布式任务调度是指通过合理的调度算法,在分布式环境下协调执行任务的一种机制。其目的是最大程度地提高任务执行效率、保障任务的可靠性和实时性。
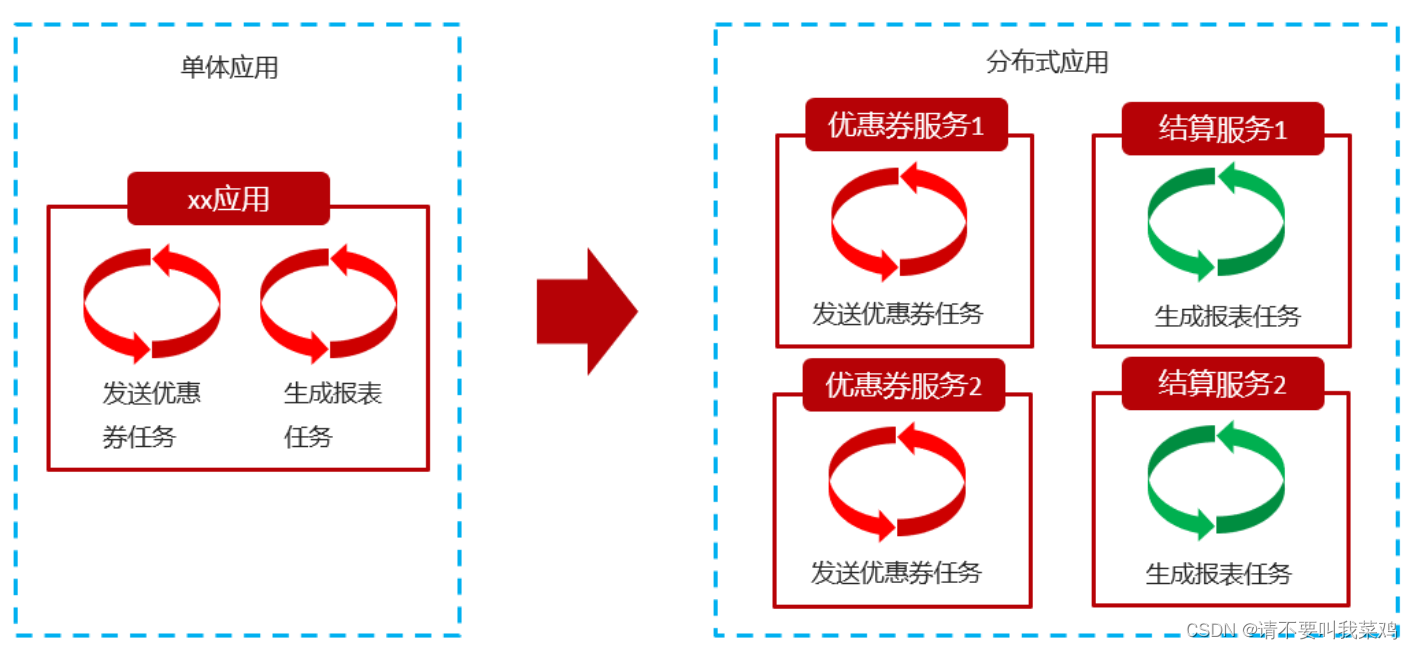
分布式任务调度主要强调两个方面:
- 分布式:在微服务架构下一个微服务实例具有多个实现,即集群模式。【分布式和微服务并不是一个概念,微服务强调的是将单个服务根据不同的业务逻辑进行拆分,而分布式强调的是针对具体的拆分的某个实例创建多个同样的服务以集群的方式存在。】
- 分布式任务调度:本质仍然是上面提到的任务调度,唯一不同的是此时针对的是一个服务实例的多个实现进行的调度。
分布式任务调度存在的问题以及解决方案
由于分布式将某个业务服务创建多个相同的服务,故在每一个服务中均存在相同的任务调度程序,此时在相同时刻多个服务中的任务调度程序均会执行,从而造成业务故障。如:电商系统定期发放优惠券,就可能重复发放优惠券,对公司造成损失,信用卡还款提醒就会重复执行多次,给用户造成烦恼,所以我们需要控制相同的任务在多个运行实例上只执行一次。
解决方案的出发点:控制相同的任务在多个运行实例上只执行一次。可以采用分布式锁、Zoopeeper选举的方式实现。
分布式锁:多个实例在任务执行前首先需要获取锁,如果获取失败那么就证明有其他服务已经在运行,如果获取成功那么证明没有服务在运行定时任务,那么就可以执行。
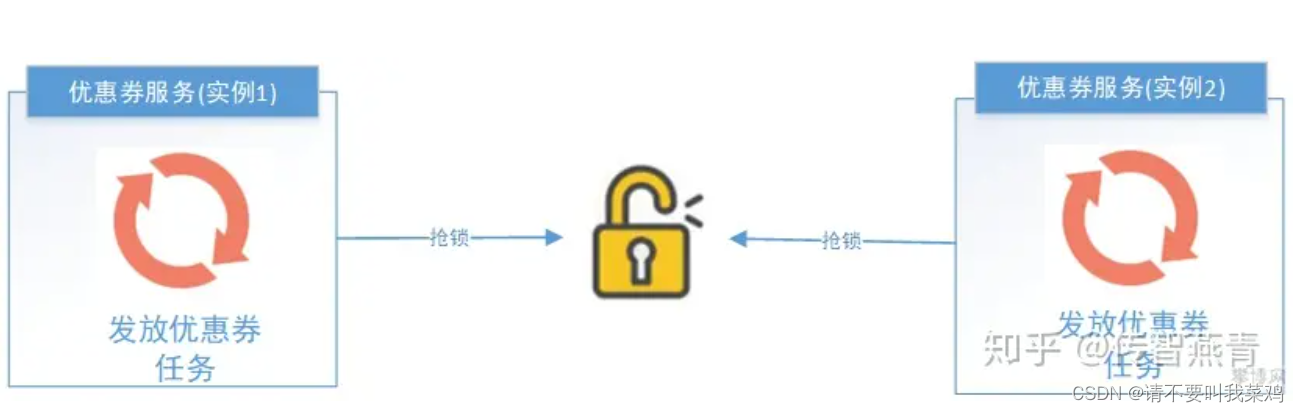
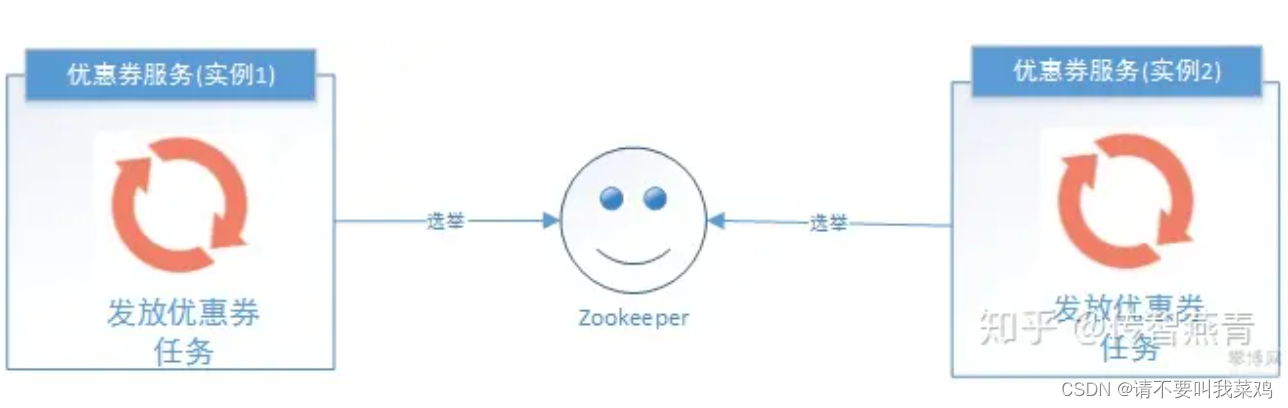
Zookeeper选举:利用ZooKeeper对Leader实例执行定时任务,执行定时任务的时候判断自己是否是Leader,如果不是则不执行,如果是则执行业务逻辑。
使用SpringTask实现单体服务的任务调度
- 添加Maven坐标。
- 启动类添加@EnableScheduling开启任务调度。
- 方法上添加@Scheduled注解,并设置cron表达式。
XXL-job分布式任务调度系统工作原理
XXL-job系统组成
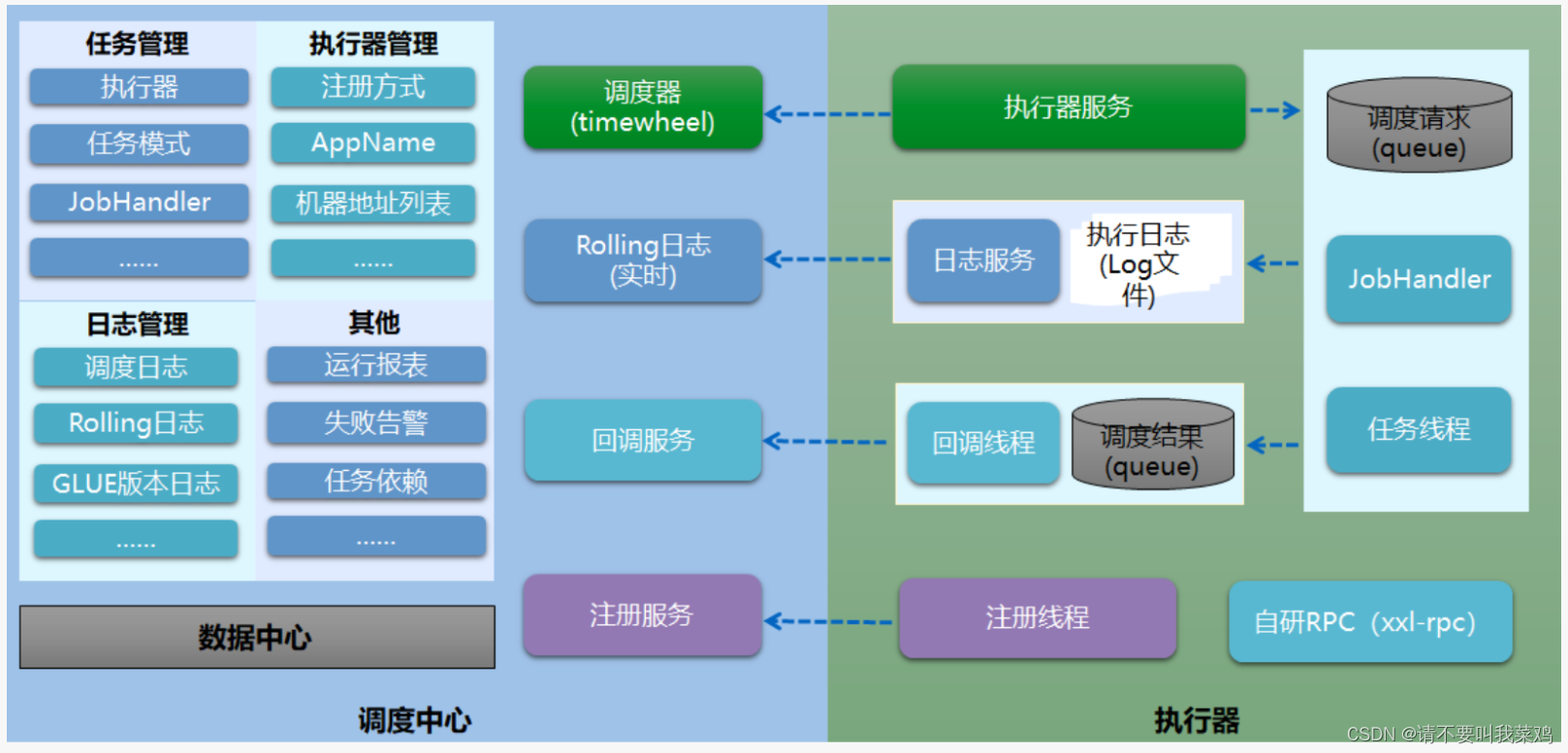
在XXL-Job的设计思路中将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性。
-
调度中心: 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover
-
执行器: 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等。
XXL-job工作原理
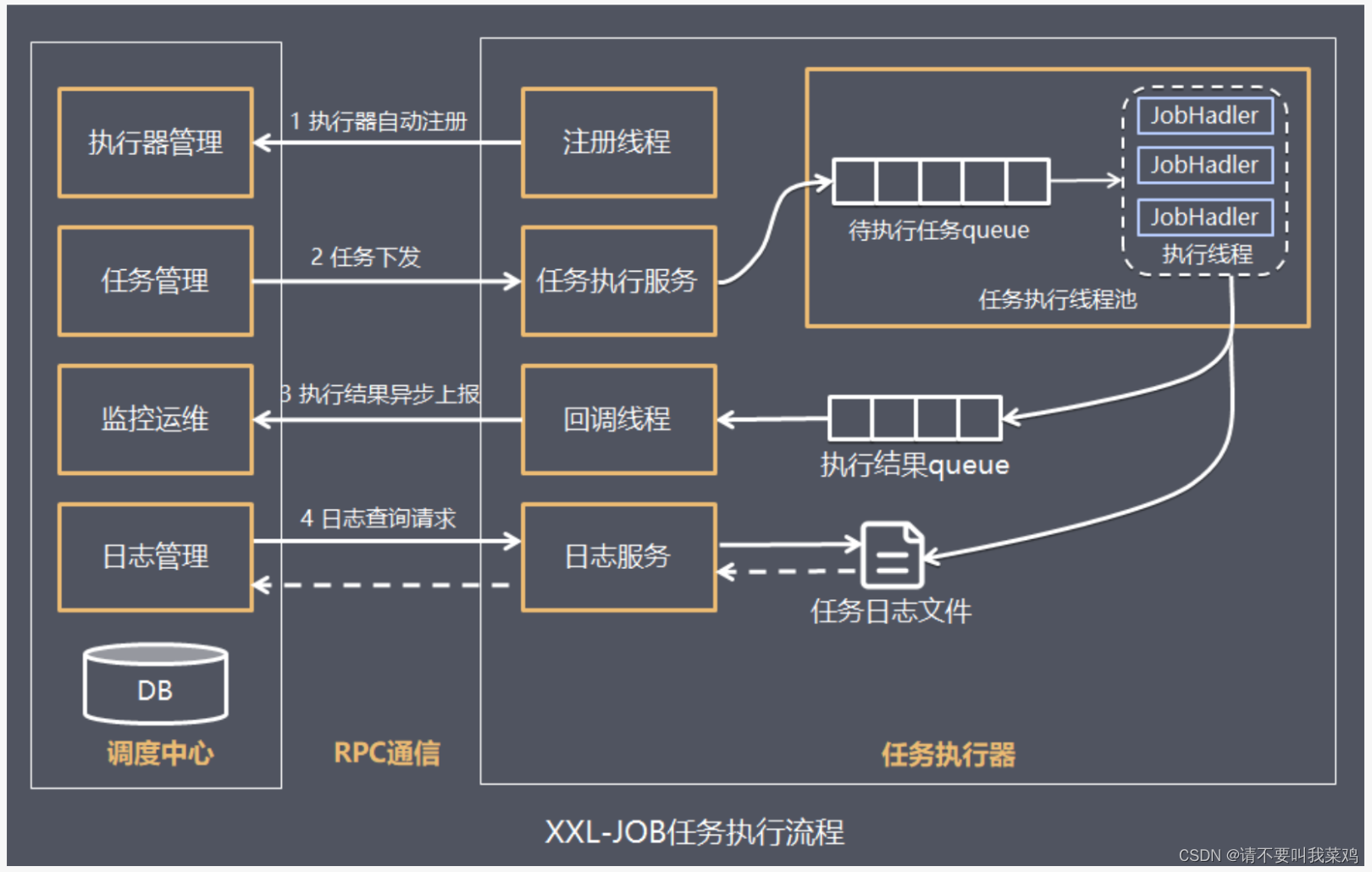
任务执行器根据配置的调度中心的地址,启动注册线程向调度中心的执行器管理发起自动注册。执行器管理中保存着注册执行器,后续会根据这个注册信息给执行器下发任务。
如果此时有需要执行的任务,任务管理模块会根据执行器管理中注册的执行器信息,向任务执行器下发任务。任务执行器中的任务执行服务接受到任务以后会将任务发送到待执行任务的队列中,队列中的任务会由执行线程JobHandler依次获取并且执行。这里会维护一个任务执行的线程池,池中就是一个个JobHandler线程,它们是执行任务的主力军。
JobHandler执行器基于线程池执行任务,并把执行结果放入执行结果队列中,同时会把执行日志写入任务日志文件中,以供日志查询。然后通知毁掉线程,告知任务执行完毕,回调线程会通知调度中心的监控运维模块,任务执行完毕。
用户可以在调度中心查看任务日志,其过程是通过发送日志查询请求给任务执行器中的日志服务,然后查询任务日志文件实现的。
使用XXL-job实现分布式任务调度
配置调度中心XXL-job
下载源码,解压并利用Maven编译。
在/xxl-job/xxl-job-admin/src/main/resources/application.properties文件中将数据库连接信息修改为自己的数据库。
启动调用中心192.168.200.130:8888/xxl-job-admin,并使用 “admin/123456”默认账号登陆。
登录调度中心创建执行器和任务


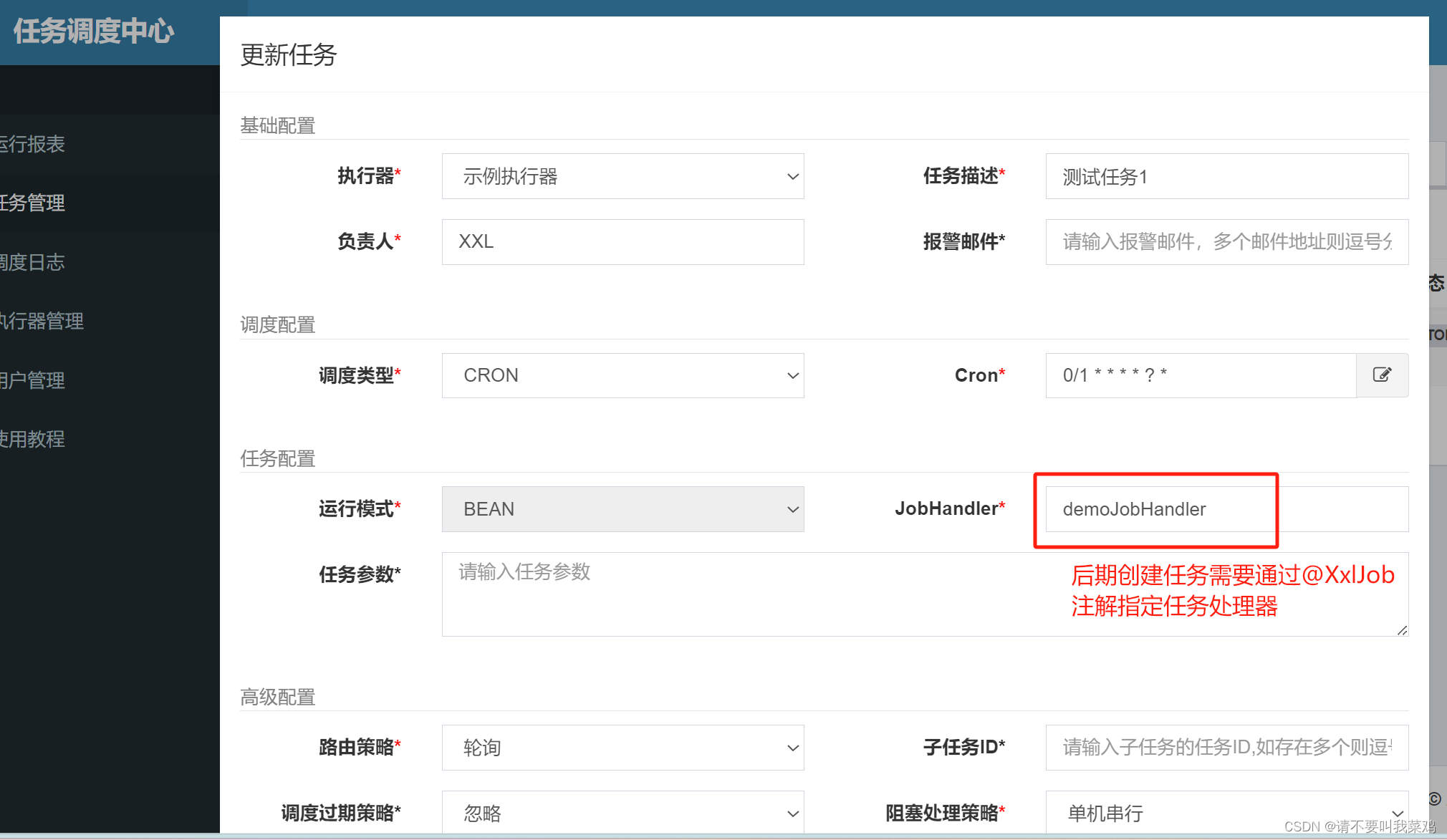
在pom文件中加入XXL-job依赖
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>2.3.0</version></dependency>在application.yml中设置参数配置
xxl:job:admin:addresses: http://192.168.200.130:8888/xxl-job-adminexecutor:appname: xxl-job-executor-sampleport: 9999配置文件中的参数在创建配置类的时候需要使用到。
创建配置类并交给Spring容器的Bean进行管理
package com.heima.xxljob.config;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** xxl-job config** @author xuxueli 2017-04-28*/
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.port}")private int port;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setPort(port);return xxlJobSpringExecutor;}}创建任务代码并通过@XxlJob注解指定处理器
package com.heima.xxljob.job;import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;@Component
public class HelloJob {//在创建任务的时候指定的处理器,可以按照指定的频率进行处理@XxlJob("demoJobHandler") public void helloJob(){System.out.println("简单任务执行了。。。。");}
}参考链接
扫盲篇-什么是分布式任务调度 - 知乎 (zhihu.com)
深度解析分布式任务调度及实现方案_分布式调度实现-CSDN博客
xxl-job工作原理解析 - 梨花压不压海棠 - 博客园 (cnblogs.com)