目录
一、overview
基础代码
核心API:
二、核心概念
2.1 加载数据
从S3上读
从本地读:
其他读取方式
读取分布式数据(spark)
从ML libraries 库中读取(不支持并行读取)
从sql中读取
2.2 变换数据
map
flat_map
Transforming batches
Shuffling rows
Repartitioning data
2.3 消费数据
1) 按行遍历
2)按batch遍历
3)遍历batch时shuffle
4)为分布式并行训练分割数据
2.4 保存数据
保存文件
修改分区数
将数据转换为python对象
将数据转换为分布式数据(spark)
今天来带大家一起来学习下ray中对数据的操作,还是非常简洁的。
一、overview
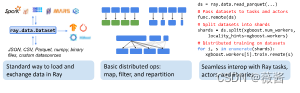
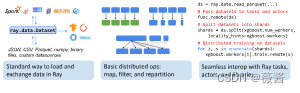
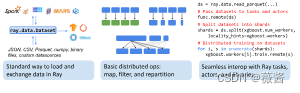
基础代码
from typing import Dict
import numpy as np
import ray# Create datasets from on-disk files, Python objects, and cloud storage like S3.
ds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv")# Apply functions to transform data. Ray Data executes transformations in parallel.
def compute_area(batch: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:length = batch["petal length (cm)"]width = batch["petal width (cm)"]batch["petal area (cm^2)"] = length * widthreturn batchtransformed_ds = ds.map_batches(compute_area)# Iterate over batches of data.
for batch in transformed_ds.iter_batches(batch_size=4):print(batch)# Save dataset contents to on-disk files or cloud storage.
transformed_ds.write_parquet("local:///tmp/iris/")使用ray.data可以方便地从硬盘、python对象、S3上读取文件
最后写入云端
核心API:
-
简单变换(map_batches())
-
全局聚合和分组聚合(groupby())
-
Shuffling 操作 (random_shuffle(), sort(), repartition()).
二、核心概念
2.1 加载数据
-
从S3上读
import ray#加载csv文件
ds = ray.data.read_csv("s3://anonymous@air-example-data/iris.csv")
print(ds.schema())
ds.show(limit=1)#加载parquet文件
ds = ray.data.read_parquet("s3://anonymous@ray-example-data/iris.parquet")#加载image
ds = ray.data.read_images("s3://anonymous@ray-example-data/batoidea/JPEGImages/")# Text
ds = ray.data.read_text("s3://anonymous@ray-example-data/this.txt")# binary
ds = ray.data.read_binary_files("s3://anonymous@ray-example-data/documents")#tfrecords
ds = ray.data.read_tfrecords("s3://anonymous@ray-example-data/iris.tfrecords")-
从本地读:
ds = ray.data.read_parquet("local:///tmp/iris.parquet")- 处理压缩文件
ds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv.gz",arrow_open_stream_args={"compression": "gzip"},
)-
其他读取方式
import ray# 从python对象里获取
ds = ray.data.from_items([{"food": "spam", "price": 9.34},{"food": "ham", "price": 5.37},{"food": "eggs", "price": 0.94}
])ds = ray.data.from_items([1, 2, 3, 4, 5])# 从numpy里获取
array = np.ones((3, 2, 2))
ds = ray.data.from_numpy(array)# 从pandas里获取
df = pd.DataFrame({"food": ["spam", "ham", "eggs"],"price": [9.34, 5.37, 0.94]
})
ds = ray.data.from_pandas(df)# 从py arrow里获取table = pa.table({"food": ["spam", "ham", "eggs"],"price": [9.34, 5.37, 0.94]
})
ds = ray.data.from_arrow(table)-
读取分布式数据(spark)
import ray
import raydpspark = raydp.init_spark(app_name="Spark -> Datasets Example",num_executors=2,executor_cores=2,executor_memory="500MB")
df = spark.createDataFrame([(i, str(i)) for i in range(10000)], ["col1", "col2"])
ds = ray.data.from_spark(df)ds.show(3)从ML libraries 库中读取(不支持并行读取)
import ray.data
from datasets import load_dataset# 从huggingface里读取(不支持并行读取)
hf_ds = load_dataset("wikitext", "wikitext-2-raw-v1")
ray_ds = ray.data.from_huggingface(hf_ds["train"])
ray_ds.take(2)# 从TensorFlow中读取(不支持并行读取)
import ray
import tensorflow_datasets as tfdstf_ds, _ = tfds.load("cifar10", split=["train", "test"])
ds = ray.data.from_tf(tf_ds)print(ds)从sql中读取
import mysql.connectorimport raydef create_connection():return mysql.connector.connect(user="admin",password=...,host="example-mysql-database.c2c2k1yfll7o.us-west-2.rds.amazonaws.com",connection_timeout=30,database="example",)# Get all movies
dataset = ray.data.read_sql("SELECT * FROM movie", create_connection)
# Get movies after the year 1980
dataset = ray.data.read_sql("SELECT title, score FROM movie WHERE year >= 1980", create_connection
)
# Get the number of movies per year
dataset = ray.data.read_sql("SELECT year, COUNT(*) FROM movie GROUP BY year", create_connection
)Ray还支持从BigQuery和MongoDB中读取,篇幅问题,不赘述了。
2.2 变换数据
变换默认是lazy,直到遍历、保存、检视数据集时才执行
map
import os
from typing import Any, Dict
import raydef parse_filename(row: Dict[str, Any]) -> Dict[str, Any]:row["filename"] = os.path.basename(row["path"])return rowds = (ray.data.read_images("s3://anonymous@ray-example-data/image-datasets/simple", include_paths=True).map(parse_filename)
)flat_map
from typing import Any, Dict, List
import raydef duplicate_row(row: Dict[str, Any]) -> List[Dict[str, Any]]:return [row] * 2print(ray.data.range(3).flat_map(duplicate_row).take_all()
)# 结果:
# [{'id': 0}, {'id': 0}, {'id': 1}, {'id': 1}, {'id': 2}, {'id': 2}]
# 原先的元素都变成2个Transforming batches
from typing import Dict
import numpy as np
import raydef increase_brightness(batch: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:batch["image"] = np.clip(batch["image"] + 4, 0, 255)return batch# batch_format:指定batch类型,可不加
ds = (ray.data.read_images("s3://anonymous@ray-example-data/image-datasets/simple").map_batches(increase_brightness, batch_format="numpy")
)如果初始化较贵,使用类而不是函数,这样每次调用类的时候,进行初始化。类有状态,而函数没有状态。
并行度可以指定(min,max)来自由调整
Shuffling rows
import rayds = (ray.data.read_images("s3://anonymous@ray-example-data/image-datasets/simple").random_shuffle()
)Repartitioning data
import rayds = ray.data.range(10000, parallelism=1000)# Repartition the data into 100 blocks. Since shuffle=False, Ray Data will minimize
# data movement during this operation by merging adjacent blocks.
ds = ds.repartition(100, shuffle=False).materialize()# Repartition the data into 200 blocks, and force a full data shuffle.
# This operation will be more expensive
ds = ds.repartition(200, shuffle=True).materialize()2.3 消费数据
1) 按行遍历
import rayds = ray.data.read_csv("s3://anonymous@air-example-data/iris.csv")for row in ds.iter_rows():print(row)2)按batch遍历
numpy、pandas、torch、tf使用不同的API遍历batch
# numpy
import ray
ds = ray.data.read_images("s3://anonymous@ray-example-data/image-datasets/simple")
for batch in ds.iter_batches(batch_size=2, batch_format="numpy"):print(batch)# pandas
import ray
ds = ray.data.read_csv("s3://anonymous@air-example-data/iris.csv")
for batch in ds.iter_batches(batch_size=2, batch_format="pandas"):print(batch)# torch
import ray
ds = ray.data.read_images("s3://anonymous@ray-example-data/image-datasets/simple")
for batch in ds.iter_torch_batches(batch_size=2):print(batch)# tf
import rayds = ray.data.read_csv("s3://anonymous@air-example-data/iris.csv")tf_dataset = ds.to_tf(feature_columns="sepal length (cm)",label_columns="target",batch_size=2
)
for features, labels in tf_dataset:print(features, labels)
3)遍历batch时shuffle
只需要在遍历batch时增加local_shuffle_buffer_size参数即可。
非全局洗牌,但性能更好。
import rayds = ray.data.read_images("s3://anonymous@ray-example-data/image-datasets/simple")for batch in ds.iter_batches(batch_size=2,batch_format="numpy",local_shuffle_buffer_size=250,
):print(batch)4)为分布式并行训练分割数据
import ray@ray.remote
class Worker:def train(self, data_iterator):for batch in data_iterator.iter_batches(batch_size=8):passds = ray.data.read_csv("s3://anonymous@air-example-data/iris.csv")
workers = [Worker.remote() for _ in range(4)]
shards = ds.streaming_split(n=4, equal=True)
ray.get([w.train.remote(s) for w, s in zip(workers, shards)])2.4 保存数据
保存文件
非常类似pandas保存文件,唯一的区别保存本地文件时需要加入local://前缀。
注意:如果不加local://前缀,ray则会将不同分区的数据写在不同节点上
import rayds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv")# local
ds.write_parquet("local:///tmp/iris/")# s3
ds.write_parquet("s3://my-bucket/my-folder")修改分区数
import os
import rayds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv")
ds.repartition(2).write_csv("/tmp/two_files/")print(os.listdir("/tmp/two_files/"))将数据转换为python对象
import rayds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv")df = ds.to_pandas()
print(df)将数据转换为分布式数据(spark)
import ray
import raydpspark = raydp.init_spark(app_name = "example",num_executors = 1,executor_cores = 4,executor_memory = "512M"
)ds = ray.data.read_csv("s3://anonymous@ray-example-data/iris.csv")
df = ds.to_spark(spark)