18.1 General
本条款描述了以下内容:
--随机变量(Random variables)
--约束块(Constraint blocks)
--随机化方法(Randomization methods)
--禁用随机化(Disabling randomization)
--控制约束(Controlling constraints)
--范围变量随机化(Scope variable randomization)
--为随机数生成器(RNG)设定种子(Seeding the random number generator (RNG))
--随机加权case语句(Random weighted case statements)
--随机序列生成(Random sequence generation)
18.2 Overview
约束驱动的测试生成允许用户自动生成用于功能验证的测试。随机测试可能比传统的直接测试方法更有效。通过指定约束,可以很容易地创建测试,这些测试可以找到难以触及的角落案例。
SystemVerilog允许用户以紧凑、声明的方式指定约束。然后由解算器处理约束,该解算器生成满足约束的随机值。随机约束通常是在面向对象的数据抽象之上指定的,该数据抽象将要随机化的数据建模为包含随机变量和用户定义约束的对象。
约束决定了可以分配给随机变量的合法值。对象是表示复杂聚合数据类型和协议(如以太网数据包)的理想对象。子条款18.3提供了基于对象的随机化和约束编程的概述。本条款的其余部分提供了有关随机变量、约束块以及用于操纵它们的机制的详细信息。
18.3 Concepts and usage
本小节介绍了在对象内生成随机激励的基本概念和用途。SystemVerilog使用面向对象的方法,根据用户定义的约束,为对象的成员变量分配随机值。例如:
class Bus;rand bit[15:0] addr;rand bit[31:0] data;constraint word_align {addr[1:0] == 2'b0;}
endclassBus类用两个随机变量addr和data对简化的总线进行建模,这两个变量表示总线上的地址和数据值。word_align约束声明addr的随机值必须使得addr是字对齐的(低位2位为0)。
调用randomize()方法为总线对象生成新的随机值:
Bus bus = new;repeat (50) beginif ( bus.randomize() == 1 )$display ("addr = %16h data = %h\n", bus.addr, bus.data);else$display ("Randomization failed.\n");
end 调用randomize()会为对象中的所有随机变量选择新值,以便所有约束都为true(满足)。
在前面的程序测试中,创建一个总线对象,然后将其随机化50次。检查每次随机化的结果是否成功。如果随机化成功,则打印addr和数据的新随机值;如果随机化失败,将打印一条错误消息。
在本例中,只有addr值受到约束,而数据值不受约束。无约束变量在其声明的范围内被赋予任何值(没有约束,可以是任何值)。
约束编程是一种强大的方法,它允许用户构建通用的、可重用的对象,这些对象稍后可以扩展或约束以执行特定的功能。该方法不同于传统的过程化编程和面向对象编程,如本例所示,它扩展了Bus类:
typedef enum {low, mid, high} AddrType;class MyBus extends Bus;rand AddrType atype;
constraint addr_range
{(atype == low ) -> addr inside { [0 : 15] };(atype == mid ) -> addr inside { [16 : 127]};(atype == high) -> addr inside {[128 : 255]};
}
endclass MyBus类继承了Bus类的所有随机变量和约束,并添加了一个名为atype的随机变量,该变量用于使用另一个约束控制地址范围。addr_range约束使用含义根据atype的随机值从三个范围约束中选择一个。当MyBus对象随机化时,将计算addr、data和atype的值,以便满足所有约束。使用继承构建分层约束系统可以开发通用模型,这些模型可以被约束以执行特定于应用程序的功能。
可以使用带有with构造的randomize()进一步约束对象,该构造声明了与对randomize的调用一致的附加约束:
task exercise_bus (MyBus bus);
int res;// EXAMPLE 1: restrict to low addressesres = bus.randomize() with {atype == low;};// EXAMPLE 2: restrict to address between 10 and 20res = bus.randomize() with {10 <= addr && addr <= 20;};// EXAMPLE 3: restrict data values to powers-of-twores = bus.randomize() with {(data & (data - 1)) == 0;};
endtask此示例说明了约束的几个重要特性,如下所示:
--约束可以是任何带有整型变量和常量的SystemVerilog表达式(例如,bit、reg、logic、integer、enum、packed struct)。
--约束求解器应能够处理广泛的方程,如代数因子分解、复杂布尔表达式以及整数和位的混合表达式。在前面的例子中,两个约束的幂是用算术方法表示的。它也可以用使用移位运算符的表达式来定义;例如,1<<n,其中n是5位随机变量。
--如果存在解决方案,则约束求解器应找到该解决方案。只有当问题受到过度约束并且没有满足约束的随机值组合时,解算器才会失败。
--约束双向交互。在本例中,为addr选择的值取决于atype及其约束方式,而为atype选择的值则取决于addr及其约束方式。所有表达式运算符都是双向处理的,包括蕴涵运算符(->)。
--约束仅支持两个状态的值。四态值(X或Z)或四态运算符(例如===,!===)是非法的,会导致错误。
--对于枚举类型的每个活动随机变量,解算器应从相应枚举定义的一组命名常量中选择一个值。解算器不应将值分配给位于其相关命名常量集之外的枚举类型的随机变量,即使该值可以成功转换为枚举类型。请注意,枚举类型的状态变量可能包含命名枚举常量集之外的值,这可能仍然允许使用有效的解决方案。
有时需要禁用对随机变量的约束。例如,要故意生成非法地址(非字节对齐):
task exercise_illegal(MyBus bus, int cycles);int res;// Disable word alignment constraint.bus.word_align.constraint_mode(0);repeat (cycles) begin// CASE 1: restrict to small addresses.res = bus.randomize() with {addr[0] || addr[1];};...end// Reenable word alignment constraintbus.word_align.constraint_mode(1);
endtask constraint_mode()方法可用于启用或禁用对象中的任何命名约束块。在这个例子中,字对齐约束被禁用,然后对象被随机分配额外的约束,迫使低阶地址位为非零(因此不对齐)。
启用或禁用约束的功能允许用户设计约束层次结构。在这些层次结构中,最低级别的约束可以表示按公共特性分组为命名约束块的物理限制,这些约束块可以独立启用或禁用。
类似地,rand_mode()方法可以用于启用或禁用任何随机变量。禁用随机变量时,其行为与其他非随机变量完全相同。
有时,希望在随机化之前或之后立即执行操作。这是通过两个内置的方法实现的,pre_randomize()和post_randomice(),它们在随机化前后自动调用。这些方法可以用所需的功能重写:
class XYPair;rand integer x, y;
endclassclass MyXYPair extends XYPairfunction void pre_randomize();super.pre_randomize();$display("Before randomize x=%0d, y=%0d", x, y);endfunctionfunction void post_randomize();super.post_randomize();$display("After randomize x=%0d, y=%0d", x, y);endfunction
endclass 默认情况下,pre_randomize()和post_randomice()调用其重写的基类方法。当重写pre_randomize()或post_randomice()时,必须小心调用基类的方法,除非该类是基类(没有基类)。否则,不应调用基类方法。
随机激励生成功能和基于面向对象约束的验证方法使用户能够快速开发涵盖复杂功能的测试,并更好地确保设计的正确性。
18.4 Random variables
类变量可以使用rand和randc类型修饰符关键字声明为随机的。在类中声明随机变量的语法如下语法18-1所示。
class_property ::= // from A.1.9{ property_qualifier } data_declaration
property_qualifier[8] ::=random_qualifier| class_item_qualifier
random_qualifier[8] ::=rand| randc [8]在任何一个声明中,只允许protected或local之一,只允许rand或randc之一,static和/或virtual只能出现一次。
语法18-1——随机变量声明语法(摘录自附录A)
--求解器可以随机化任何整数类型的奇异变量。
--数组可以声明为rand或randc,在这种情况下,其所有成员元素都被视为rand或者randc。
--可以约束单个数组元素,在这种情况下,索引表达式可以包括迭代约束循环变量、常量和状态变量。
--动态数组、关联数组和队列可以声明为rand或randc。数组中的所有元素都是随机化的,覆盖以前的任何数据。
--声明为rand或randc的动态数组或队列的大小也可以受到约束。在这种情况下,应根据大小约束调整数组的大小,然后对所有数组元素进行随机化。数组大小约束是使用size方法声明的。例如:
rand bit [7:0] len;
rand integer data[];
constraint db { data.size == len; } 变量len被声明为8位宽。随机化器计算在0到255的8位范围内的len变量的随机值,然后将data数组大小随机化为len元素的值。当通过randomize()调整动态数组的大小时,调整大小的数组将使用原始数组进行初始化(见7.5.1)。当通过randomize()调整队列大小时,根据需要在队列的后面(即右侧)插入或删除元素(见7.10.2.2和7.10.2.3),以产生新的队列大小;插入的任何新元素都采用元素类型的默认值。也就是说,调整大小会增大或缩小数组。这对于类句柄的动态数组或队列非常重要。randomize()不分配任何类对象。
在新的大小之前,将保留现有的类对象,并对其内容进行随机化。如果新的大小大于原始大小,则每个附加元素都有一个不需要随机化的空值。在通过randomize()或new调整动态数组或队列的大小时,保留每个保留元素的rand_mode,并将每个新元素的rand_mod设置为active。如果动态数组的大小不受约束,则不应调整数组的大小,并且应随机化所有数组元素。
--对象句柄可以声明为rand,在这种情况下,该对象的所有变量和约束都与包含句柄的对象的变量和约束同时求解。随机化不应修改实际对象句柄。对象句柄不应声明为randc。
--一个未封装的结构可以声明为rand,在这种情况下,该结构的所有随机成员都可以使用本小节中列出的规则之一同时求解。未包装的结构不得声明为randc。未封装结构的成员可以通过在其类型的声明中使用rand或randc修饰符而变得随机。
例如:
class packet;typedef struct {randc int addr = 1 + constant;int crc;rand byte data [] = {1,2,3,4};} header;rand header h1;
endclasspacket p1=new; --未封装的 unions不得声明为rand或randc。
--封装的标签unions不得声明为rand或randc。
--封装的未标记unions可以声明为rand或randc,在这种情况下,该unions被视为整型。封装无标签unions的成员不得随意修改。
--封装结构可以声明为rand或randc,在这种情况下,该结构被视为整数类型。封装结构的成员不应随机修改。
--如果封装结构或封装未标记unions类型的rand变量具有枚举类型的成员,则18.3中限制枚举变量随机值的规则不适用于该成员。
例如:
typedef enum bit [1:0] { A=2'b00, B=2'b11 } ab_e;typedef struct packed {ab_e ValidAB;
} VStructEnum;typedef union packed {ab_e ValidAB;
} VUnionEnum; 当随机化ab_e类型的变量时,解算器只能选择2’b00或2’b11(分别为A或B)的随机值。
但是,当随机化类型为VStructEnum或VUnioEnum的变量时,解算器可以选择2’b00、2’b01、2’b10或2’b11。
18.4.1 Rand modifier
用rand关键字声明的变量是标准随机变量。它们的值在其范围内均匀分布。
例如:
rand bit [7:0] y;这是一个8位无符号整数,范围为0到255。如果不受约束,则应以相同的概率为该变量分配0至255范围内的任何值。在这个例子中,在对randomize()的连续调用中重复相同值的概率是1/256。
18.4.2 Randc modifier
用randc关键字声明的变量是随机循环变量,在其声明范围的随机排列中循环所有值。要理解randc,请考虑一个2位随机变量y:
变量y可以取值0、1、2和3(范围为0到3)。randomize()计算y的范围值的初始随机排列,然后在连续调用时按顺序返回这些值。在返回排列的最后一个元素后,它通过计算新的随机排列来重复该过程。其基本思想是randc随机迭代该范围内的所有值,并且在迭代中不重复任何值。
当迭代结束时,一个新的迭代会自动开始(见图18-1)。每当对任何给定随机变量的约束改变时,或者当排列中的剩余值都不能满足约束时,重新计算该变量的排列序列。排列序列应仅包含两个状态值。为了减少内存需求,实现可能会对randc变量的最大大小施加限制,但不得小于8位。
随机循环变量的语义要求它们在其他随机变量之前被求解。应求解包括rand和randc变量的一组约束,以便首先求解randc变量,这有时会导致randomize()失败。
如果随机变量被声明为静态,则该变量的随机状态也应为静态。因此,当变量在基类的任何实例中随机化时,randomize()选择下一个循环值(来自单个序列)。
18.5 Constraint blocks
随机变量的值是使用使用约束块声明的约束表达式来确定的。约束块是类成员,如任务、函数和变量。约束块名称在一个类中应是唯一的。声明约束块的语法如下语法18-2所示。
constraint_declaration ::= // from A.1.10[ static ] constraint constraint_identifier constraint_block
constraint_block ::= { { constraint_block_item } }
constraint_block_item ::=solve solve_before_list before solve_before_list ;| constraint_expression
solve_before_list ::= constraint_primary { , constraint_primary }
constraint_primary ::= [ implicit_class_handle . | class_scope ] hierarchical_identifier select
constraint_expression ::=[ soft ] expression_or_dist ;| expression –> constraint_set| if ( expression ) constraint_set [ else constraint_set ]| foreach ( ps_or_hierarchical_array_identifier [ loop_variables ] ) constraint_set| disable soft constraint_primary ;
constraint_set ::=
constraint_expression| { { constraint_expression } }
dist_list ::= dist_item { , dist_item }
dist_item ::= value_range [ dist_weight ]
dist_weight ::=:= expression| :/ expression
constraint_prototype ::= [constraint_prototype_qualifier] [ static ] constraint constraint_identifier ;
constraint_prototype_qualifier ::= extern | pure
extern_constraint_declaration ::=[ static ] constraint class_scope constraint_identifier constraint_block
identifier_list ::= identifier { , identifier }
expression_or_dist ::= expression [ dist { dist_list } ] // from A.2.10
loop_variables ::= [ index_variable_identifier ] { , [ index_variable_identifier ] }语法18-2——约束语法(摘录自附录A)
constraint_identifier是约束块的名称。此名称可用于使用constraint_mode()方法启用或禁用约束(请参见18.9)。
constraint_block是一个表达式语句列表,用于限制变量的范围或定义变量之间的关系。
constraint_expression是任何SystemVerilog表达式或特定于约束的操作符dist和->之一(分别参见18.5.4和18.5.6)。
约束的声明性对约束表达式施加了以下限制:
--允许有某些限制的功能(见18.5.12)。
--不允许使用带有副作用的运算符,如++和--。
--randc变量不能在排序约束中指定(请参阅18.5.10中的solve…before)。
--dist表达式不能出现在其他表达式中。
18.5.1 External constraint blocks
如果约束原型出现在封闭类声明中,则可以在其封闭类声明之外声明约束块。约束原型指定类应具有指定名称的约束,但不指定用于实现该约束的约束块。约束原型可以采用两种形式中的任意一种,如以下示例所示:
class C;rand int x;constraint proto1; // implicit formextern constraint proto2; // explicit form
endclass对于这两种形式,可以通过使用类范围解析运算符提供外部约束块来完成约束,如以下示例所示:
constraint C::proto1 { x inside {-4, 5, 7}; }
constraint C::proto2 { x >= 0; }
class CBA;rand bit[7:0] x;rand bit[7:0] src;constraint proto1; // implicit form// constraint proto2 { x inside {-4, 5, 7}; } // explicit formrand integer xx;endclassconstraint CBA::proto1 { x inside {-4, 5, 7}; }module tb;CBA cinst,cinst1,cinst2,cinst3,cinst4;initial begincinst=new();cinst1=new();cinst.randomize();cinst1.randomize();#100 $display("cinst. x is %d \n",cinst.x);#100 $display("cinst. x is %d \n",cinst1.x);end
endmodule 外部约束块应出现在与相应类声明相同的范围内,并应出现在该范围内的类声明之后。如果使用约束原型的显式形式,如果没有提供相应的外部约束块,则为错误。如果使用原型的隐式形式,并且没有相应的外部约束块,则该约束应被视为空约束,并可能发出警告。空约束是指对随机化没有影响的约束,相当于包含常量表达式1的约束块。
对于任何一种形式,如果为任何给定的原型提供了一个以上的外部约束块,则为错误;如果在同一类声明中出现了与原型同名的约束块,那么为错误。
18.5.2 Constraint inheritance
约束与其他类成员遵循相同的继承通用规则。randomize()方法是虚拟的,因此无论调用该方法的对象句柄的数据类型如何,它都会遵守调用对象的约束。派生类应继承其超类的所有约束。
派生类中的任何约束与其超类中的约束同名,都应替换该名称的继承约束。派生类中与超类中的约束名称不相同的任何约束都应是附加约束。
如果派生类的约束原型与其超类中的约束同名,则该约束原型应替换继承的约束。派生类的约束原型的完成应遵循18.5.1中描述的规则。
抽象类(即,如8.21所述,使用语法虚拟类声明的类)可以包含纯约束(pure constraints)。纯约束(pure constraints)在语法上类似于约束原型,但使用pure关键字,如以下示例所示:
virtual class D;pure constraint Test;
endclass 纯约束表示对任何非抽象派生类(即非虚拟派生类)提供相同名称约束的义务。如果一个非抽象类没有它继承的每个纯约束的实现,那将是一个错误。在非抽象类中声明纯约束是错误的。
如果包含纯约束的类也有同名的约束块、约束原型或外部约束块,则这将是一个错误。然而,任何类(无论是否抽象)都可能包含与该类继承的纯约束同名的约束块或约束原型;这样的约束应覆盖纯约束,并且应是类及其派生的任何类的非纯约束。
从其超类继承约束的抽象类可能具有同名的纯约束。在这种情况下,派生的虚拟类中的纯约束应取代继承的约束。覆盖纯约束的约束可以使用覆盖类主体中的约束块来声明,也可以使用约束原型和外部约束来声明,如18.5.1所述。
18.5.3 Set membership
约束支持整数值集和集合成员运算符(如11.4.13中所定义)。在没有任何其他约束的情况下,所有值(单个值或值范围)被内部运算符选择的概率相等。内部运算符的否定形式表示表达式位于集合之外:!({set}内的表达式)。例如:
rand integer x, y, z;
constraint c1 {x inside {3, 5, [9:15], [24:32], [y:2*y], z};}
rand integer a, b, c;
constraint c2 {a inside {b, c};}
integer fives[4] = '{ 5, 10, 15, 20 };
rand integer v;
constraint c3 { v inside {fives}; }
在SystemVerilog中,inside 运算符是双向的;因此,前面的第二个例子等效于a==b ||a==c。
18.5.4 Distribution
除了集合成员之外,约束还支持称为分布的加权值集合。分布有两个属性:它们是集合成员关系的关系测试,并为结果指定统计分布函数。定义分布表达式的语法如下语法18-3所示。
constraint_expression ::= // from A.1.10expression_or_dist ;...
dist_list ::= dist_item { , dist_item }
dist_item ::= value_range [ dist_weight ]
dist_weight ::=:= expression| :/ expression
expression_or_dist ::= expression [ dist { dist_list } ]语法18-3——约束分布语法(摘录自附录A)
该表达式可以是任何整数型的SystemVerilog表达式。
如果表达式的值包含在集合中,则分布运算符dist的计算结果为true;否则,它的计算结果为false。
在没有任何其他约束的情况下,表达式匹配列表中任何值的概率与其指定的权重成比例。如果某些表达式上存在导致这些表达式上的分布权重不可满足的约束,则只需要实现来满足这些约束。此规则的一个例外是权重为零,它被视为约束。
分布集是一个以逗号分隔的整数表达式和范围列表。(可选)列表中的每个术语都可以有一个权重,该权重是使用:=或:/运算符指定的。如果没有为项目指定权重,则默认权重为:=1。
权重可以是任何整数SystemVerilog表达式。
:=运算符将指定的权重分配给项目,如果项目是一个范围,则分配给该范围中的每个值。
:/运算符将指定的权重分配给项目,或者,如果项目是一个范围,则将指定权重分配给整个范围。
如果该范围中有n个值,则每个值的权重为range_weight/n。
例如:
x dist {100 := 1, 200 := 2, 300 := 5}意味着x等于100、200或300,加权比为1-2-5。如果添加了指定x不能是200的附加约束,
x != 200;
x dist {100 := 1, 200 := 2, 300 := 5}则x等于100或300,加权比率为1-5。
考虑混合比(如1-2-5)比实际概率更容易,因为混合比不必归一化为100%。将概率转换为混合比率很简单。
将权重应用于范围时,可以将其应用于范围中的每个值,也可以将其作为一个整体应用于范围。例如:
x dist { [100:102] := 1, 200 := 2, 300 := 5}表示x等于100、101、102、200或300,加权比为1-1-1-2-5,以及
x dist { [100:102] :/ 1, 200 := 2, 300 := 5} 意味着x等于100、101、102、200或300中的一个,加权比为1/3-1/3-1/3-2-5。
一般来说,分布保证两个性质:集合成员和单调加权。换句话说,增加权重会增加选择这些值的可能性。
限制如下:
--dist运算不应应用于 randc变量。
--dist表达式要求该表达式至少包含一个rand变量。
18.5.5 Uniqueness constraints
可以使用唯一约束来约束一组变量,以便随机化后该组的两个成员都不具有相同的值。应使用open_range_list语法的受限形式指定要约束的变量组,其中逗号分隔列表中的每个项目应为以下项目之一:
--整数型标量变量
--一个未封装的数组变量,其叶元素类型为整型,或该变量的切片
constraint_expression ::= // from A.1.10...| uniqueness_constraint ;
uniqueness_constraint ::=unique { open_range_list }uniqueness_constraint中的open_range_list应仅包含表示标量或数组变量的表达式,如18.5.5所述。
语法18-4——唯一性约束语法(摘录自附录A)
未封装数组的叶元素是通过向下遍历数组直到到达非未封装数组类型的元素来找到的。
如此指定的变量组的所有成员(即任何标量变量以及任何数组或切片的所有叶元素)应为等效类型。组中不应出现randc变量。
如果如此指定的变量组包含少于两个成员,则约束不应产生任何影响,也不应引起约束矛盾。
在以下示例中,变量a[2]、a[3]、b和excluded在随机化后都将包含不同的值。由于exclusion约束,变量a[2]、a[3]和b都不包含值5。
rand byte a[5];
rand byte b;
rand byte excluded;
constraint u { unique {b, a[2:3], excluded}; }
constraint exclusion { excluded == 5; }18.5.6 Implication
约束为声明条件关系提供了两种构造:蕴涵和if-else。蕴涵运算符(–>)可用于声明包含约束的表达式。定义隐含约束的语法如下语法18-5所示。
constraint_expression ::= // from A.1.10...| expression –> constraint_set语法18-5——约束隐含语法(摘录自附录A)
该表达式可以是任何整型SystemVerilog表达式。
蕴涵运算符a->b的布尔等价项是(!a||b)。这表示如果表达式为true,则生成的随机数受约束(或约束集)的约束。否则,生成的随机数是不受约束的。
constraint_set表示任何有效的约束或未命名的约束集。如果表达式为true,则约束集中的所有约束也应得到满足。
例如:
在本例中,mode的值意味着len的值应限制为小于10(mode==little)、大于100(mode==big)或不受约束(mode!=little和mode!=big)。
在示例中:
rand bit [3:0] a, b;
constraint c { (a == 0) -> (b == 1); }a和b都是4比特;因此,有256个a和b的组合。约束c表示,a==0意味着b==1,从而消除了15个组合:{0,0},{0,2},…{0,15}。因此,a==0的概率因此是1/(256-15)或1/241。
18.5.7 if–else constraints
还支持if–else样式约束。定义if–else约束的语法如下语法18-6所示。
constraint_expression ::= // from A.1.10...| if ( expression ) constraint_set [ else constraint_set ]语法18-6-If–else约束语法(摘录自附录A)
该表达式可以是任何整数型SystemVerilog表达式。
constraint_set表示任何有效的约束或未命名的约束集。如果表达式为真,则应满足第一约束或约束集中的所有约束;否则,应满足可选的else约束或约束集中的所有约束。
约束集可用于对多个约束进行分组。if–else样式的约束声明等效于含义
if (mode == little)len < 10;
else if (mode == big)len > 100;相当于
mode == little -> len < 10 ;
mode == big -> len > 100 ; 在本例中,mode的值意味着len的值小于10、大于100或不受约束。就像言外之意一样,if–else样式约束也是双向的。在前面的声明中,mode的值约束len的值,len的值则约束mode的值。
因为if–else样式约束声明的else部分是可选的,所以当从嵌套的if序列中省略else时可能会出现混淆。如果没有else,则通过始终将else与最近的前一个关联来解决此问题。在以下示例中,else与内部if一起使用,如缩进所示:
if (mode != big)if (mode == little)len < 10;else // the else applies to preceding iflen > 100;18.5.8 Iterative constraints
迭代约束允许使用循环变量和索引表达式或使用数组归约方法来约束阵列变量。
18.5.8.1 foreach iterative constraints
定义foreach迭代约束的语法如下语法18-7所示。
constraint_expression ::= // from A.1.10...| foreach ( ps_or_hierarchical_array_identifier [ loop_variables ] ) constraint_set
loop_variables ::= [ index_variable_identifier ] { , [ index_variable_identifier ] } // from A.6.8
语法18-7——Foreach迭代约束语法(摘录自附录A)
foreach构造指定在数组的元素上进行迭代。它的参数是一个标识符,用于指定任何类型的数组(固定大小、动态、关联或队列),后跟方括号中的循环变量列表。每个循环变量对应于数组的一个维度。
例如:
class C;rand byte A[] ;constraint C1 { foreach ( A [ i ] ) A[i] inside {2,4,8,16}; }constraint C2 { foreach ( A [ j ] ) A[j] > 2 * j; }
endclass C1将数组A的每个元素约束在集合[2,4,8,16]中。 C2将阵列A的每个元素约束为大于其索引的两倍。
循环变量的数量不得超过数组变量的维数。每个循环变量的作用域是foreach约束构造,包括其constraint_set。每个循环变量的类型都隐式声明为与数组索引的类型一致。空循环变量表示在数组的该维度上没有迭代。与默认参数一样,末尾的逗号列表可以省略;因此,foreach(arr[j])是foreach(arr[j,,])的简写。
任何循环变量的标识符与数组相同都是错误的。循环变量到数组索引的映射由维度基数决定,如20.7所述:
// 1 2 3 3 4 1 2 -> Dimension numbers
int A [2][3][4]; bit [3:0][2:1] B [5:1][4];
foreach( A [ i, j, k ] ) ...
foreach( B [ q, r, , s ] ) ...
第一个foreach使i从0到1迭代,j从0到2迭代,k从0到3迭代。第二个foreach使q从5到1迭代,r从0到3迭代,s从2到1迭代。foreach迭代约束可以包括预声明。
例如:
class C;rand int A[] ;constraint c1 { A.size inside {[1:10]}; }constraint c2 { foreach ( A[ k ] ) (k < A.size - 1) -> A[k + 1] > A[k]; }
endclass 第一个约束条件c1将阵列A的大小约束为在1和10之间。第二个约束c2将每个数组值约束为大于前一个值,即按升序排序的数组。
在foreach中,仅涉及常量、状态变量、对象句柄比较、循环变量或正在迭代的数组大小的预声明表达式的行为是防止创建约束,而不是逻辑关系。例如,上面约束c2中的含义仅涉及循环变量和正在迭代的数组的大小;因此,只有当k<a.size()-1时,它才允许创建约束,在这种情况下,这可以防止在约束中进行越界访问。
索引表达式可以包括循环变量、常量和状态变量。无效或越界的数组索引不会自动消除;用户必须使用预声明明确地排除这些索引。可以使用动态数组或队列的大小方法来约束数组的大小(参见上面的约束c1)。如果阵列同时受到大小约束和迭代约束的约束,则首先求解大小约束,然后求解迭代约束。由于大小约束和迭代约束之间的这种隐式排序,大小方法应被视为相应数组的foreach块内的状态变量。例如,表达式A.size在约束c1中被当作随机变量,在约束c2中被当作状态变量。这种隐式排序可能会导致求解器在某些情况下失败。
循环变量到数组索引的映射由维度基数决定,如20.7中所述。
第一个foreach使i从0到1迭代,j从0到2迭代,k从0到3迭代。
第二个foreach使q从5到1迭代,r从0到3迭代,s从2到1迭代。foreach迭代约束可以包括声明。例如
class C;rand int A[] ;constraint c1 { A.size inside {[1:10]}; }constraint c2 { foreach ( A[ k ] ) (k < A.size - 1) -> A[k + 1] > A[k]; }endclass 第一个约束条件c1将阵列A的大小约束为在1和10之间。第二个约束c2将每个数组值约束为大于前一个值,即按升序排序的数组。
在foreach中,仅涉及常量、状态变量、对象句柄比较、循环变量或正在迭代的数组大小的声明表达式的行为是防止创建约束,而不是逻辑关系。例如,上面约束c2中的含义仅涉及循环变量和正在迭代的数组的大小;因此,只有当k<a.size()-1时,它才允许创建约束,在这种情况下,这可以防止在约束中进行越界访问。
索引表达式可以包括循环变量、常量和状态变量。无效或越界的数组索引不会自动消除;用户必须使用声明明确地排除这些索引。
可以使用动态数组或队列的大小方法来约束数组的大小(参见上面的约束c1)。如果数组同时受到大小约束和迭代约束的约束,则首先求解大小约束,然后求解迭代约束。由于大小约束和迭代约束之间的这种隐式排序,大小方法应被视为相应数组的foreach块内的状态变量。例如,表达式A.size在约束c1中被当作随机变量,在约束c2中被当作状态变量。这种隐式排序可能会导致求解器在某些情况下失败。
18.5.8.2 Array reduction iterative constraints
数组归约方法可以从未封装的整型值数组中生成单个整型值(见7.12.3)。在约束的上下文中,数组归约方法被视为在数组的每个元素上迭代的表达式,由每个方法的相关操作数连接。结果返回与数组元素类型相同类型的单个值,如果指定了该值,则返回with子句中表达式的类型。
例如:
class C;rand bit [7:0] A[] ;constraint c1 { A.size == 5; }constraint c2 { A.sum() with (int'(item)) < 1000; }endclass约束c2将被解释为
( int'(A[0])+int'(A[1])+int'(A[2])+int'(A[3])+int'(A[4]) ) < 100018.5.9 Global constraints
当一个类的对象成员被声明为rand时,它的所有约束和随机变量将与其他类变量和约束同时随机化。涉及其他对象的随机变量的约束表达式称为全局约束(见图18-2)。
class A; // leaf noderand bit [7:0] v;endclassclass B extends A; // heap noderand A left;rand A right;constraint heapcond {left.v <= v; right.v > v;}
endclass
此示例使用全局约束来定义有序二叉树的合法值。类A表示具有8位值v的叶节点。类B扩展了类A,表示一个值为v的堆节点、一个左子树和一个右子树。两个子树都被声明为rand,以便与其他类变量同时随机化它们。名为heapcond的约束块有两个全局约束,将左子树值和右子树值与堆节点值相关联。当类B的实例被随机化时,解算器同时求解B及其左右两个子节点,这两个子节点又可以是叶节点或更多堆节点。
以下规则确定要随机化的对象、变量和约束:
a) 首先,确定要作为一个整体随机化的对象集。从调用randomize()方法的对象开始,添加其中包含的、声明为rand的和活动的所有对象(请参见18.8中的rand_mode)。该定义是递归的,包括可以从起始对象到达的所有活动随机对象。在此步骤中选择的对象称为活动随机对象。
b) 其次,从一组活动随机对象中选择所有活动约束。这些是应用于问题的约束条件。
c) 第三,从一组活动随机对象中选择所有活动随机变量。这些是要随机化的变量。所有其他变量引用都被视为状态变量,其当前值被用作常数。
18.5.10 Variable ordering
求解器应确保随机值的选择在合法值组合上给出均匀的值分布(即,合法值的所有组合都具有相同的求解概率)。这一重要性质保证了所有合法值组合的可能性相等,从而允许随机化更好地探索整个设计空间。然而,有时需要强制某些组合更频繁地发生。考虑1位控制变量s约束32位数据值d的情况:
class B;rand bit s;rand bit [31:0] d;constraint c { s -> d == 0; }endclass 约束条件c表示s意味着d等于零。虽然这读起来好像s决定了d,但实际上s和d是一起决定的。{s,d}有1+2的32次方个合法值组合,但s仅对其中一个为真。表18-1列出了每种合法值组合及其发生概率:
表18-1——无序约束c合法值概率
约束提供了一种对变量排序的机制,使得可以独立于d来选择s。此机制定义了变量求值的排序,并使用solve关键字指定。
class B;rand bit s;rand bit [31:0] d;constraint c { s -> d == 0; }constraint order { solve s before d; }
endclass 在这种情况下,顺序约束指示解算器在求解d之前先求解s。其效果是,现在以50/50%的概率选择s为0或1,然后根据s的值选择d。添加此顺序约束不会改变合法值组合的集合,但会改变其发生的概率,如表18-2所示:
Table 18-2—Ordered constraint c legal value probability
在没有顺序约束的情况下,d==0的概率为1/(1+2的32次方),接近于0;在有顺序约束的情况下,概率为1/2*1/(2的32次方),略高于50%。
可变排序可用于强制选定的corner情况比其他情况下更频繁地发生。但是,“solve...before...”约束不会更改解算空间,因此不会导致解算器失败。
在约束块中定义变量顺序的语法如下语法18-8所示。
constraint_block_item ::= // from A.1.10solve solve_before_list before solve_before_list ;| constraint_expression
solve_before_list ::= solve_before_primary { , solve_before_primary }
solve_before_primary ::= [ implicit_class_handle . | class_scope ] hierarchical_identifier select Syntax 18-8—Solve...before constraint ordering syntax (excerpt from Annex A)
以下限制适用于变量排序:
--只允许使用随机变量,也就是说,它们应该是rand。
--不允许使用randc变量。randc 变量总是先于其他变量求解。
--变量应为整数值。
--约束块可以包含规则值约束和排序约束。
--排序中不应存在循环依赖关系,例如“在b之前解决a”与“在a之前解决b”相结合
--未明确排序的变量应使用最后一组排序变量进行求解。这些值被推迟到尽可能晚的时候,以确保值的良好分布。
--部分排序的变量应使用最新的一组排序变量求解,以满足所有排序约束。这些值被推迟到尽可能晚的时候,以确保值的良好分布。
--变量可以按照与排序约束不一致的顺序求解,前提是结果相同。可能发生这种情况的示例如下:
x == 0;
x < y;
solve y before x;在这种情况下,因为x只有一个可能的赋值(0),所以x可以在y之前求解。约束求解器可以使用这种灵活性来加快求解过程。
18.5.11 Static constraint blocks
通过在约束块的定义中包含static关键字,可以将其定义为static。声明静态约束块的语法如下语法18-9所示。
constraint_declaration ::= // from A.1.10[ static ] constraint constraint_identifier constraint_block Syntax 18-9—Static constraint syntax (excerpt from Annex A)
如果约束块被声明为静态,那么对constraint_mode()的调用将影响所有对象中指定约束的所有实例。因此,如果静态约束设置为OFF,则该特定类的所有实例都处于OFF状态。
当使用约束原型和外部约束块声明约束时,static 关键字应同时应用于约束原型和外约束块,或者两者都不应用。如果其中一个限定为静态而另一个不是,这将是一个错误。类似地,纯约束可以是限定静态的,但任何重写约束都必须匹配纯约束的限定或不存在。
18.5.12 Functions in constraints
有些属性很难或不可能在单个表达式中表达。例如,计算压缩数组中1个数的自然方法使用循环:
function int count_ones ( bit [9:0] w );for( count_ones = 0; w != 0; w = w >> 1 )count_ones += w & 1'b1;
endfunction这样的函数可以用于将其他随机变量约束为1比特的数量:
constraint C1 { length == count_ones( v ) ; }在没有调用函数的能力的情况下,此约束要求循环展开并表示为单个位的总和:
constraint C2{length == ((v>>9)&1) + ((v>>8)&1) + ((v>>7)&1) + ((v>>6)&1) + ((v>>5)&1) +((v>>4)&1) + ((v>>3)&1) + ((v>>2)&1) + ((v>>1)&1) + ((v>>0)&1);
} 与count_ones函数不同,需要临时状态或无边界循环的更复杂的属性可能无法转换为单个表达式。因此,调用函数的能力增强了约束语言的表达能力,并降低了出错的可能性。上述两个约束条件C1和C2并不完全等效;C2是双向的(长度可以约束v,反之亦然),而C1不是。
为了处理这些常见情况,SystemVerilog允许约束表达式包括函数调用,但它施加了某些语义限制,如下所示:
--出现在约束表达式中的函数不能包含output或ref参数(允许使用const ref)。
--出现在约束表达式中的函数应该是automatic(或者不保留状态信息),并且没有副作用。
--出现在约束中的函数不能修改约束,例如,调用rand_mode或constraint_mode方法。
--函数应在求解约束之前调用,其返回值应视为状态变量。
--用作函数自变量的随机变量应建立隐式变量排序或优先级。
仅包括优先级较高的变量的约束在其他优先级较低的约束之前得到解决。作为更高优先级约束集的一部分求解的随机变量成为剩余约束集的状态变量。
例如
class B;rand int x, y;constraint C { x <= F(y); }constraint D { y inside { 2, 4, 8 } ; }endclass 迫使y在x之前求解。因此,在使用y和F(y)的值作为状态变量的约束C之前,单独求解约束D。在SystemVerilog中,函数自变量隐含的变量排序行为与使用“solve…before…”约束指定的排序行为不同;函数自变量变量排序细分了解空间,从而改变了它。因为对优先级较高的变量的约束是在根本不考虑优先级较低的约束的情况下求解的,所以这种细分可能会导致整体约束失败。在每个按优先级排列的约束集中,首先求解循环(randc)变量。
--由隐式变量排序创建的循环依赖关系将导致错误。
--活动约束中的函数调用以未指定的顺序执行未指定的次数(至少一次)。
18.5.13 Constraint guards
约束保护是预测表达式,其作用是防止创建约束,而不是作为求解器要满足的逻辑关系。这些预测表达式在求解约束之前进行求值,其特征在于仅涉及以下项:
--常量
--状态变量
--对象句柄比较(两个句柄或一个句柄与常量null之间的比较)
除此之外,迭代约束(见18.5.8)还考虑循环变量和数组的大小被迭代为状态变量。
将这些预测表达式视为约束保护可以防止求解器生成求值错误,从而在某些看似正确的约束上失败。这使得用户能够编写约束,以避免由于不存在对象句柄或数组索引越界而导致的错误。
例如,下面显示的单链表SList的排序约束旨在分配一个按升序排序的随机数字序列。但是,当next.n由于不存在句柄而导致计算错误时,约束表达式将在最后一个元素上失败。
class SList;rand int n;rand Slist next;constraint sort { n < next.n; }
endclass可以通过编写预测表达式来避免这种错误情况:
constraint sort { if( next != null ) n < next.n; } 在前面的排序约束中,if在next==null时阻止创建约束,这在本例中避免了访问不存在的对象。言外之意(–>)和if…else都可以用作保护。保护表达式本身可以包括导致计算错误(例如,空引用)的子表达式,并且还可以保护它们不生成错误。这种逻辑筛选是通过使用以下4状态表示来评估谓词子表达式来完成的:
--0 FALSE 子表达式的计算结果为FALSE。
--1 TRUE 子表达式的计算结果为TRUE。
--E ERROR 子表达式会导致计算错误。
--R RANDOM 表达式包含随机变量,无法计算。
预测表达式中的每个子表达式都被求值以产生前四个值中的一个。子表达式按任意顺序求值,该求值的结果加上逻辑运算定义了备用4状态表示的结果。子表达式的连接(&&)、析取(||)或否定(!)可以包括一些(也许是所有)保护子表达式。以下规则指定保护的结果值:
—拼接(&&)。如果任何一个子表达式的计算结果为FALSE,则保护的计算结果将为FALSE。如果任何一个子表达式的计算结果为ERROR,则保护的计算结果将为ERROR。
否则,保护评估为TRUE。
•如果保护评估结果为FALSE,则限制被消除。
•如果保护评估为TRUE,则生成一个(可能是有条件的)约束。
•如果保护评估为ERROR,则会生成一个错误,randomize()将失败。
--Disjunction(||):如果任何一个子表达式的计算结果为TRUE,则保护的计算结果将为TRUE。如果任何一个子表达式的计算结果为ERROR,则保护的计算结果将为ERROR。
否则,保护评估结果为FALSE。
•如果保护评估为FALSE,则生成一个(可能是有条件的)约束。
•如果保护评估为TRUE,则生成无条件约束。
•如果保护评估为ERROR,则会生成一个错误,randomize()将失败。
--否定(!):如果子表达式的计算结果为ERROR,则保护的计算结果将为ERROR。否则,如果子表达式的计算结果为TRUE或FALSE,则保护的计算结果分别为FALSE或TRUE
这些规则由图18-3所示的真值表编码。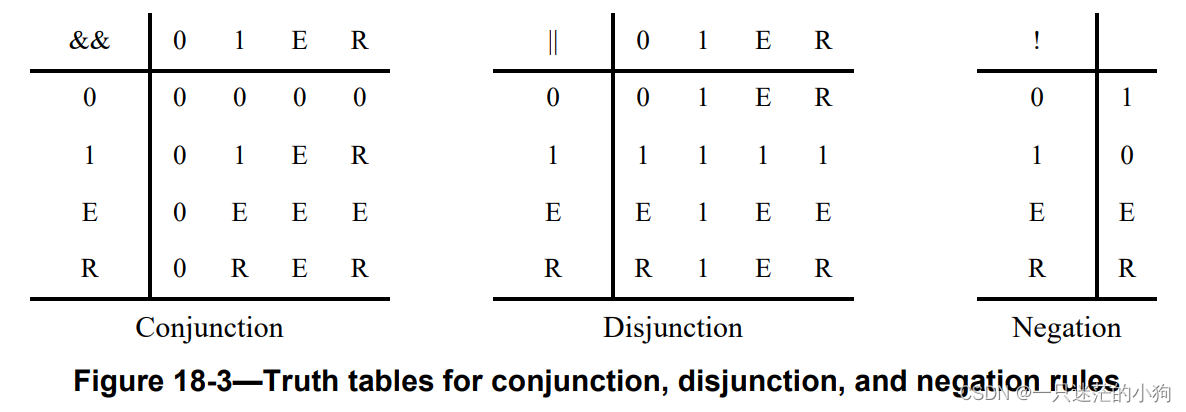
这些规则被递归地应用,直到所有子表达式都被求值为止。计算的预测表达式的最终值决定结果,如下所示:
--如果结果为TRUE,则生成一个无条件约束。
--如果结果为FALSE,则约束将被消除,并且不会产生错误。
--如果结果为ERROR,则会生成一个无条件错误,并且约束失败。
--如果评估的最终结果是RANDOM,则生成条件约束。
当最终值为RANDOM时,需要遍历谓词表达式树来收集所有计算结果为RANDOM的条件保护。当最终值为ERROR时,不需要对表达式树进行后续遍历,从而允许实现只发出一个错误。
示例1:
class D;int x;
endclassclass C;rand int x, y;D a, b;constraint c1 { (x < y || a.x > b.x || a.x == 5 ) -> x+y == 10; }
endclass 在示例1中,谓词子表达式是(x<y)、(a.x>b.x)和(a.x==5),它们都通过 || 连接。 一些可能的情况如下:
--情况1:a为非空,b为空,a.x为5。因为(a.x==5)为真,b.x生成错误的事实不会导致错误。生成无条件约束(x+y==10)。
--情况2:a为null。不管其他条件如何,这总是会导致错误。
--情况3:a为非空,b为非空。a.x为10,b.x为20。所有保护子表达式的计算结果均为FALSE。生成条件约束(x<y)->(x+y==10)。
示例2:
class D;int x;
endclassclass C;rand int x, y;D a, b;constraint c1 { (x < y && a.x > b.x && a.x == 5 ) -> x+y == 10; }
endclass 在示例2中,预测子表达式是(x<y)、(a.x>b.x)和(a.x==5),它们都通过&&连接。
一些可能的情况如下:
--情况1:a为非空,b为空,a.x为6。因为(a.x==5)为假,b.x生成错误的事实不会导致错误。约束被消除。
--情况2:a为空不管其他条件如何,这总是会导致错误。
--情况3:a为非空,b为非空。a.x为5,b.x为2。所有保护子表达式的计算结果均为TRUE,从而产生约束(x<y)->(x+y==10)。
示例3:
class D;int x;
endclassclass C;rand int x, y;D a, b;constraint c1 { (x < y && (a.x > b.x || a.x ==5)) -> x+y == 10; }
endclass 在示例3中,预测子表达式是(x<y)和(a.x>b.x||a.x==5),它们通过||连接。一些可能的情况如下:
--情况1:a为非空,b为空,a.x为5。保护表达式的计算结果为(ERROR||a.x==5),其计算结果是(ERROR|| TRUE)保护子表达式的计算结果为TRUE。生成条件约束(x<y)->(x+y==10)。
--情况2:a为非空,b为空,a.x为8。保护表达式的计算结果为(ERROR||FALSE)并生成一个错误。
--情况3:a为空,不管其他条件如何,这总是会导致错误。
--情况4:a为非空,b为非空。a.x为5,b.x为2。所有保护子表达式的计算结果均为TRUE。
生成条件约束(x<y)->(x+y==10)。
18.5.14 Soft constraints
到目前为止描述的约束可以表示为硬约束,因为解算器必须始终满足这些约束,否则将导致解算器失败。相反,当没有解决方案同时满足所有活动的硬约束(如果有的话)和定义为软约束时,解算器应放弃该软约束,并找到满足其余约束的解决方案。如果有两个或两个以上的软约束表达式不能同时满足,则应按照18.5.14.1的规定丢弃软约束。
软约束使通用验证块的作者能够提供更容易扩展的完整工作环境,因为约束求解器自动忽略由后续更专业的约束覆盖的通用软约束。软约束通常用于指定随机变量的默认值和分布。例如,通用数据包类的作者可能会添加一个约束,以确保默认情况下生成合法大小的数据包(没有任何其他约束):
class Packet;
rand bit mode;
rand int length;constraint deflt {soft length inside {32,1024};soft mode -> length == 1024;// Note: soft mode -> {length == 1024;} is not legal syntax,// as soft must be followed by an expression
}
endclassPacket p = new();
p.randomize() with { length == 1512;} // mode will randomize to 0
p.randomize() with { length == 1512; mode == 1;} // mode will randomize to 1如果{32,1024}内的约束表达式长度未定义为soft,则对randomize()的调用将失败,需要特别注意。失败可以通过显式关闭约束(这需要额外的过程代码)来解决,或者通过使用新的类来扩展基类并用新的类覆盖约束(这会使测试显著复杂化)来解决。相反,由软约束指定的默认值会自动覆盖,这会导致更简单的分层测试。
18.6 Randomization methods
18.6.1 Randomize()
对象中的变量使用randomize()类方法进行随机化。每个类都有一个内置的randomize()虚拟方法,声明如下:
virtual function int randomize(); randomize()方法是一个虚拟函数,它根据活动约束为对象中的所有活动随机变量生成随机值。如果randomize()方法成功地将所有随机变量和对象设置为有效值,则返回1;否则,返回0。
示例:
class SimpleSum;rand bit [7:0] x, y, z;constraint c {z == x + y;}
endclass这个类定义声明了三个随机变量,x、y和z。调用randomize()方法将使类SimpleSum的实例随机化:
SimpleSum p = new;
int success = p.randomize();
if (success == 1 ) ...检查返回状态可能是必要的,因为状态变量的实际值或在派生类中添加约束可能会使看似简单的约束无法满足要求。
18.6.2 Pre_randomize() and post_randomize()
每个类都包含pre_randomize()和post_randomiize()方法,它们在计算新的随机值之前和之后由randomize()自动调用。pre_randomize()方法的原型如下:
function void pre_randomize();
post_randomize()方法的原型如下:
function void post_randomize(); 当调用obj.randomize()时,它首先调用obj上的pre_randomize()。计算并分配新的随机值后,randomize()调用obj上的post_randomize()。
用户可以重写任何类中的pre_randomize(),以便在对象随机化之前执行初始化并设置先决条件。如果该类是派生类,并且不存在pre_randomize()的用户定义实现,那么pre_randimize()将自动调用super.pre_randomize()。
用户可以覆盖任何类中的post_randomize(),以便在对象随机化后执行清理、打印诊断和检查post条件。如果该类是派生类,并且不存在post_randomize()的用户定义实现,那么post_randimize()将自动调用super.post_randomice()。
如果这些方法被重写,它们将调用与其关联的基类方法;否则,应跳过其随机化前和随机化后的处理步骤。
pre_randomize()和post_randomice()方法不是虚拟的。然而,因为它们是由randomize()方法自动调用的,这是虚拟的,所以它们看起来像是虚拟方法。
18.6.3 Behavior of randomization methods
--声明为静态的随机变量由声明它们的类的所有实例共享。每次调用randomize()方法时,每个类实例中的变量都会发生变化。
--如果randomize()失败,则约束是不可行的,并且随机变量保留其以前的值。
--如果randomize()失败,则不会调用post_randomize()。
--randomize()方法是内置的,不能重写。
--randomize()方法实现了对象的随机稳定性。一个对象可以通过调用其srandom()方法来播种(见18.13.3)。
--内置方法pre_randomize()和post_randomice()是函数,不能阻塞。
18.7 In-line constraints—randomize() with
通过使用randomize()with构造,用户可以在调用randomize()方法的位置声明内联约束。这些附加约束将与对象约束一起应用。randomize()的语法如下语法18-10所示。
inline_constraint _declaration ::= // not in Annex Aclass_variable_identifier . randomize [ ( [ variable_identifier_list | null ] ) ]with [ ( [ identifier_list ] ) ] constraint_block
randomize_call ::= // from A.1.10randomize { attribute_instance }[ ( [ variable_identifier_list | null ] ) ][ with [ ( [ identifier_list ] ) ] constraint_block ]在不是类类型对象的方法调用的randomize_call(即作用域randomize)中,关键字with后面的可选加括号的identifier_list是非法的,使用null是非法的。
Syntax 18-10—Inline constraint syntax (excerpt from Annex A)
class_variable_identifier是实例化对象的名称。
未命名的constraint_block包含要与类中声明的对象约束一起应用的其他内嵌约束。
示例:
class SimpleSum;rand bit [7:0] x, y, z;constraint c {z == x + y;}
endclasstask InlineConstraintDemo(SimpleSum p);int success;success = p.randomize() with {x < y;};
endtask 这与之前使用的示例相同;然而,randomize()with 构造用于引入一个额外的约束,即x<y。randomize()with 构造可以用于表达式可能出现的任何位置。后面的约束块可以定义所有与在类中声明的约束类型和形式相同的约束。
带约束块的randomize()with还可以引用局部变量和子例程参数,从而无需将局部状态镜像为对象类中的成员变量。如果约束块前面没有可选的带括号的identifier_list,则认为约束块不受限制。无限制约束块中引用的变量名的解析范围以对象类的randomize()with开始;也就是说,在对randomize()with的方法调用中使用的对象句柄的类。然后,如果名称未能在具有对象类的randomize()with中解析,则通常从包含内联约束的范围开始解析该名称。由this或super限定的名称应绑定到方法的randomize()with调用中使用的对象句柄的类。因此,如果限定名称未能在对象类的randomize()with中解析,则将是一个错误。除this或super限定的名称外的点名称应首先以向下的方式解析(见23.3),从对象类的randomize()with范围开始。如果虚名称没有在对象类的randomize()with范围内解析,则应在包含内联约束的范围内按照正常解析规则解析。
local::限定符(请参见18.7.1)用于绕过(randomize(with object)类的作用域,并在包含randomize)方法调用的(local)作用域中开始名称解析过程。当constraint_block前面有可选的带括号的identifier_list时,约束块被认为是受限制的。在受限约束块中,只有名称解析以identifier_list中的标识符开始的变量才能解析为对象类的randomize();所有其他名称应从包含randomize()方法调用的作用域开始解析。当带括号的identifier_list存在并且使用local::限定符时,限定名称应从包含randomize()方法调用的作用域开始解析,而与名称是否存在于identifier_list中无关。