GPT-NEOX使用旋转位置编码。模型权重使用float16表示。最大序列长度为2048。
论文题目:2022.04.14_GPT-NeoX-20B: An Open-Source Autoregressive Language Model
论文地址:2204.06745.pdf (arxiv.org)
论文代码:EleutherAI/gpt-neox: An implementation of model parallel autoregressive transformers on GPUs, based on the DeepSpeed library. (github.com)
Demo:GPT-NeoX (huggingface.co)
论文详解
概述
介绍了 GPT-NeoX-20B,这是一个在 Pile【1】 数据集上训练的 200 亿参数自回归语言模型,其权重是开源的。在这项工作中,描述了 GPT-NeoX-20B 的架构和训练,并评估了其在一系列语言理解方面的性能, 数学和基于知识的任务。GPT-NeoX-20B 是一个特别强大的小样本推理器,并且 在评估时,性能比类似大小的 GPT-3 和 FairSeq 模型高得多。是开源训练和评估代码以及模型权重。
1.模型架构
- GPT-NeoX-20B 是一种自回归 transformer 解码器模型,它在很大程度上遵循了 GPT-3 的模型,但有一些明显的偏差。
- 该模型有 200 亿个参数、44 层、隐藏维度大小为 6144 和 64 个头。
旋转位置嵌入
- 与 RoFormer 一样,使用旋转嵌入代替 GPT 模型中使用的学习位置嵌入。
在基础的位置嵌入上,关于m位置的token,注意力在m-n上,做线性依赖的嵌入空间进行提取

也就是Xm和Xn是各位置出现的,已经处理之后的m和n的token嵌入,Wtq和Wk是下面公式的查询(query)和key的权重
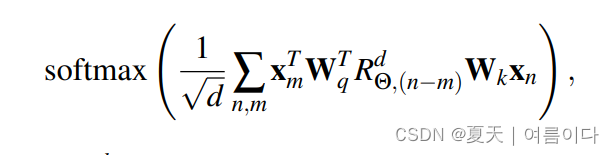
换句话说,如下图,
如果Enhanced的位置编码是1,经过编码后如虚线部分位置,通过公式进行变换(回传)编码部分。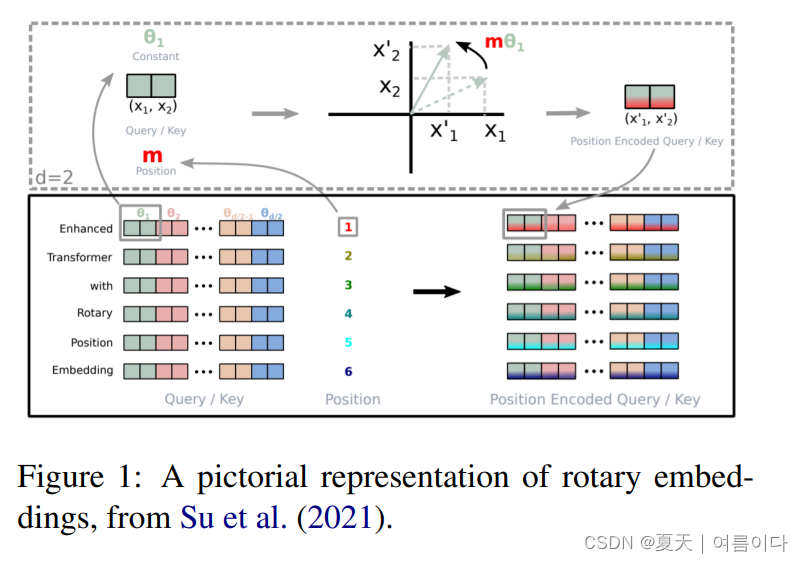
在GPT-NeoX-20B中旋转嵌入适作用于编码向量的前25%,早期实验结果中证明性能和计算的有效性相对来说比较好。
更加高效的训练
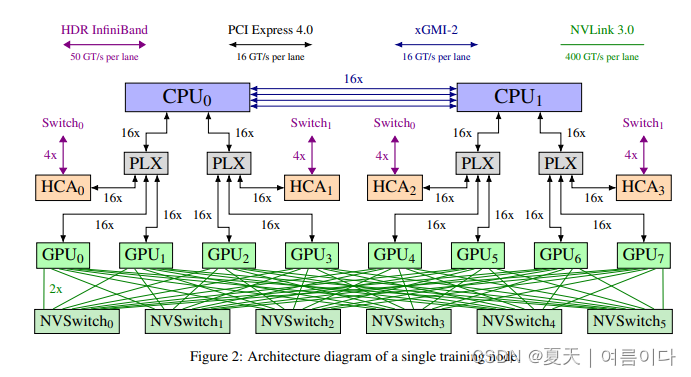
并行注意力和全连接层
为了提高计算效率,需要并行计算和添加注意力层和前馈层。
初始化
在前馈输出层中,使用了可定义为 2/L√d 的初始化架构。(为防止激活随着深度和宽度的增加而变大。
密集层
GPT3 在密集层和稀疏层之间交替,而 GPT-NeoX-20B 仅使用密集层来降低实现复杂性。
2.训练
基于数据集Pile训练
Tokenization: BPE
3.结果
3.1.自然语言任务
GPT-NeoX-20B在某些任务(如ARC、LAMBADA、PIQA、PROST)上的表现优于FairSeq 13B,而在其他任务上表现较差。(例如 HellaSwag、LogiQA Zero-Shot)。在 32 项任务中,22 项表现良好,4 项表现不佳,6 项在误差范围内。
GPT-NeoX-20B在HellaSwag上的性能最低,在Zero-Shot和Five-Shot设置下的得分比FairSeq 13B低四倍。
3.2.数学任务
对于数学问题,GPT-3 和 FairSeq 模型的表现相似,而 GPT-J 和 GPT-NeoX 模型的表现始终更好。鉴于 GPT-J 与 Pile 数据集中许多方程的相关性,可以假设这是由于数据造成的,由于训练数据不公开,因此很难验证它们。
3.3.高级任务
在基于知识的高级任务中,MMMLU(多学科多项选择题)GPT-NeoX 和 FairSeq 模型优于 GPT-3,在五轮学习中尤为突出。
在之前的研究中,Zero-Shot 和 Few-Shot 之间的性能差异并不显著,但在 GPT-NeoX 和 FairSeq 模型的情况下,发现 Zero-Shot 之间的差异可以忽略不计,而当增加到 Five-Shot 时,性能提升明显更大。
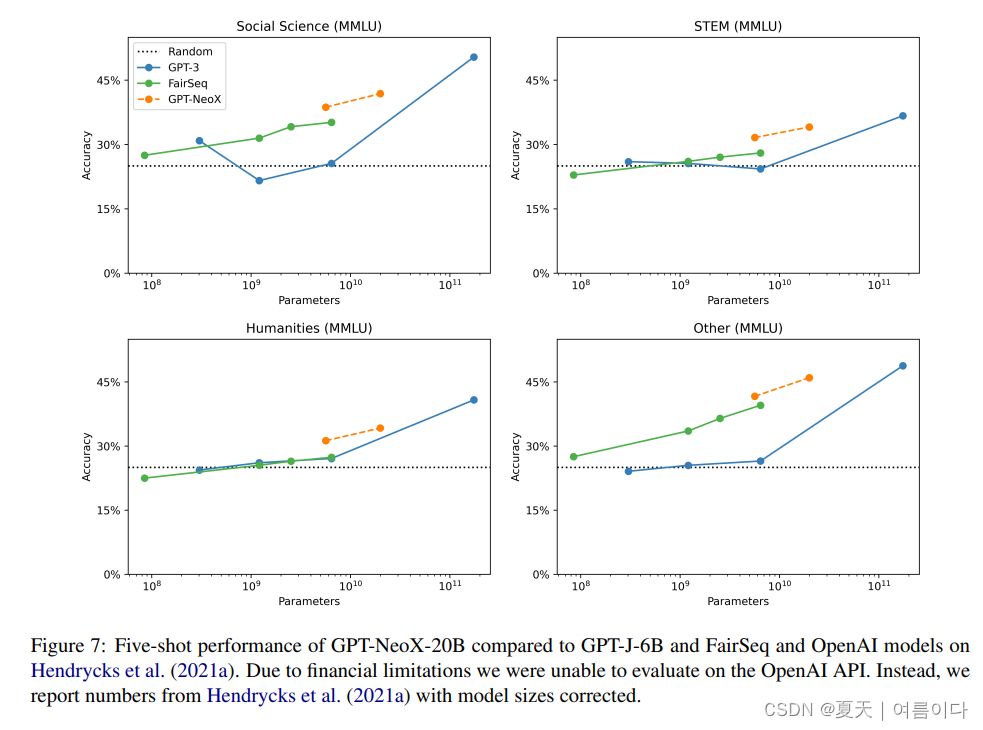
强大的小样本学习
实验结果表明,与FairSeq模型相比,GPT-J和GPT-NeoX在Few-Shot设置中具有明显更大的优势。
与Zero-Shot相比,GPT-J-6B和GPT-NeoX-20B分别提高了0.0526和0.0598,而FairSeq 6.7B和13B型号分别提高了0.0051和0.0183。
扩展
大模型训练流程
- 数据并行:模型的参数被复制到每个GPU上。每个GPU负责处理一部分独立的训练数据,并计算梯度。然后,这些梯度被汇总并应用于更新模型参数。这样,每个GPU都在处理整个模型的一部分数据,从而加速训练。
- Batch Size:批量大小通常被等分到每个GPU上。例如,如果你有4个GPU,每个GPU可能处理总批量大小的1/4。
- 模型参数同步:在训练过程中,模型参数需要在不同的GPU之间同步,以确保它们保持一致。这可以通过梯度汇总和模型参数更新来实现。在深度学习框架中,通常会使用反向传播算法来计算每个GPU上的梯度,然后将这些梯度汇总起来,最后应用于更新模型参数。
- 数据分发:训练数据需要被分发到不同的GPU上。这可以通过数据切片或数据分区的方式实现。确保每个GPU都有足够的训练数据以进行有效的学习。
- 模型架构:在训练大型语言模型时,通常会使用分层的模型结构,以便更好地适应多GPU的训练。例如,可以使用分布式的Transformer架构。
- 内存管理:确保每个GPU的显存都足够容纳模型参数、梯度和训练数据。对于大型语言模型,可能需要特别注意内存的管理,以避免显存不足的问题。
参考文献
【1】Datasheet for the Pile – arXiv Vanity (arxiv-vanity.com)
【2】Review — GPT-NeoX-20B: An Open-Source Autoregressive Language Model | by Sik-Ho Tsang | Medium【3】Relative Positional Encoding - Jake Tae

![[linux][调度] linux 下如何观察线程调度延时 ?](https://img-blog.csdnimg.cn/direct/27829c547721421bb7efdcec61c87d2a.png)