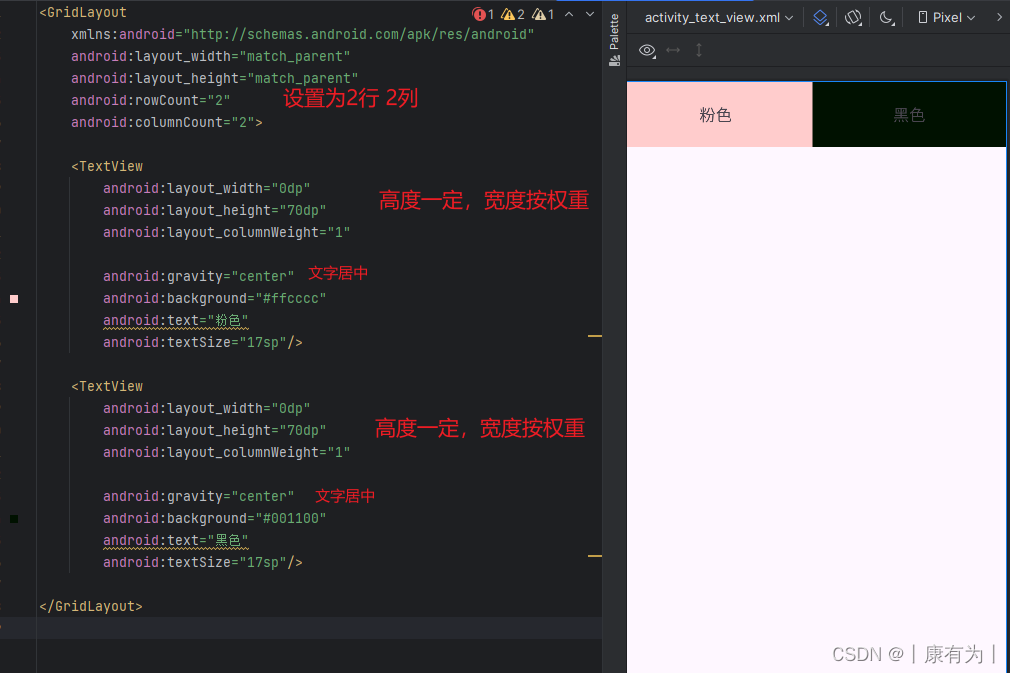
1.1搭建爬虫程序开发环境
爬取未来七天天气预报
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
url="http://www.weather.com.cn/weather/101120901.shtml"
try:headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}req=urllib.request.Request(url,headers=headers)data=urllib.request.urlopen(req)data=data.read()dammit=UnicodeDammit(data,["utf-8","gbk"])data=dammit.unicode_markupsoup=BeautifulSoup(data,"lxml")lis=soup.select("ul[class='t clearfix'] li")for li in lis:try:date=li.select('h1')[0].textweather=li.select('p[class="wea"]')[0].texts=li.select_one('p[class="tem"] span')i=li.select_one('p[class="tem"] i')temp=""if s:temp+=s.textif i:temp+="/"+i.textprint(date,weather,temp)except Exception as err:print(err)
except Exception as err:print(err)
1.2创建Flask Web 服务器
安装Flask
Python清华源: https://pypi.tuna.tsinghua.edu.cn/simple
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple flask
#更新flask版本
pip install -U flask
Web服务器
import flask
##初始化一个Flask对象,参数__name__是程序的名称
#也可以给这个app起个别的名字app=flask.Flask("web")
app=flask.Flask(__name__)
#路由,映射到服务器的跟地址,如果用跟地址访问此Web服务器则执行hello函数
@app.route("/")
def hello():html="<h1>大家好</h1>"html+="<a href='/hi'>sai hi</a>"return html
@app.route("/hi")
def hi():html="<h1>Hi</h1>"html+="<a href='/'>说你好</a>"return html
#如果这是一个主程序,则执行app.run
if __name__=="__main__":# 打开服务器的调试模式,使用Run Without debuggingapp.debug=True
#默认端口号为5000app.run(port=5000)
web服务器返回HTML文件
import flask
##初始化一个Flask对象,参数__name__是程序的名称
app=flask.Flask(__name__)
#路由,映射到服务器的跟地址,如果用跟地址访问此Web服务器则执行index函数
@app.route("/")
def index():try:fobj=open("index.html","rb")data=fobj.read()fobj.close()return dataexcept Exception as err:return str(err)
if __name__=="__main__":app.run()使用python请求自己的服务器
import urllib.request
url="http://127.0.0.1:5000"
#打开此网址,获取这个网址的一个响应,数据
html=urllib.request.urlopen(url)
#打开这个网址后读取他的数据,注意此时读取出来的为二进制数据
html=html.read()
#将读取出来的二进制数据转换成字符串
#decode默认编码为utf-8编码,即默认为decode("utf-8")
#若转换不同可以考虑gbk编码decode("gbk")
html=html.decode()
print(html)
web图像文件显示
import flask
##初始化一个Flask对象,参数__name__是程序的名称
#也可以给这个app起个别的名字app=flask.Flask("web")
app=flask.Flask(__name__)
…………
@app.route("/img")
def retimg():fobj=open("html/images/erha.jpg","rb")data=fobj.read()fobj.close()
#告诉浏览器返回的文件类型,浏览器应该怎样解析
#默认解析为“text/html”
#"plain/text"的话会默认下载该文件response=flask.make_response(data)response.headers["content-type"]="image/jpeg"return response
if __name__=="__main__":# 打开服务器的调试模式app.debug=Trueapp.run()
静态文件显示
#创建一个静态文件夹static
import flask
##初始化一个Flask对象,参数__name__是程序的名称
#也可以给这个app起个别的名字app=flask.Flask("web")
app=flask.Flask(__name__)
####----------------------------------------------------------
@app.route("/imgTag")
def imgTag():#经测试,文件路径应为当前文件夹下的static中的文件#也可以在创建app时进行指定html="<h1>Image</h1><img src='static/images/erha.jpg' width='200'>"return html
if __name__=="__main__":# 打开服务器的调试模式app.debug=Trueapp.run()
指定静态文件夹
import flask
##初始化一个Flask对象,参数__name__是程序的名称
#也可以给这个app起个别的名字app=flask.Flask("web")
#指定默认静态文件夹
app=flask.Flask(__name__,static_folder="../html")
#路由,映射到服务器的跟地址,如果用跟地址访问此Web服务器则执行index函数
……
@app.route("/imgTag")
def imgTag():html="<h1>Image</h1><img src='html/images/erha.jpg' width='200'>"return html
if __name__=="__main__":# 打开服务器的调试模式app.debug=Trueapp.run()
客户端访问服务器
………
@app.route("/plates")
def plates():return flask.render_template("index.html")
…………

自己爬取自己服务器
import urllib.request
url="http://127.0.0.1:5000"
resp=urllib.request.urlopen(url)
data=resp.read()
print(data)
html=data.decode()
print(html)
1.3使用GET方法访问网站
格式:url+?名称1+值1&名称2=值2&名称3=值3
urllib.resquest.urlopen("http://127.0.0.1:5000?province=GD&city=SZ")
#若传递的数据中有汉字,则需要编码
province=urllib.parse.quote("广东")
city=urllib.parse.quote("深圳")
urllib.resquest.urlopen("http://127.0.0.1:5000?province="+province+"&city="+city)
#这样传递过去汉字就不会出现乱码
#相反的unquote()
GET方法访问网站 & 服务器端获取数据
import urllib.parse
import urllib.request
url="http://127.0.0.1:5000/getM"
try:province=urllib.parse.quote("广东")city=urllib.parse.quote("深圳")data="province="+province+"&city="+cityhtml=urllib.request.urlopen(url+"?"+data)html=html.read()html=html.decode()print(html)
except Exception as err:print(err)
-----------------------------------------------------------
import flask
app=flask.Flask(__name__,static_folder="html")
@app.route("/getM")
def getM():#province=flask.request.args.get("province") if "province" in flask.request.args else ""#city=flask.request.args.get("city") if "city" in flask.request.args else ""#若没有值则返回赋值为空province=flask.request.values.get("province","")city=flask.request.values.get("city","")return province+","+city
if __name__=="__main__":# 打开服务器的调试模式app.debug=Trueapp.run(port=5000)
中英文调整
import flask
app=flask.Flask(__name__,static_folder="html")
@app.route("/english")
def english():language=flask.request.values.get("language","english")if language=="chinese":html="你好"else:html="hello"return htmlimport urllib.parse
import urllib.request
url="http://127.0.0.1:5000/english"
try:data="?language=chinese"html=urllib.request.urlopen(url+data)html=html.read()html=html.decode()print(html)
except Exception as err:print(err)
翻译
import flask
app=flask.Flask("web")
@app.route("/")
def index():dict={"苹果":"apple","桃子":"peach","梨子":"pear"}word=flask.request.values.get("word","")s=""if word in dict.keys():s=dict[word]elif word:s="对不起,字典里面没有"return s
app.debug=True
app.run()import urllib.request
import urllib.parse
url="http://127.0.0.1:5000"
word=input("请输入中文:")
#不能直接向浏览器发送中文
#quote将中文转换成十六进制编码
word=urllib.parse.quote(word)
print(word)
#unquote将十六进制编码转换成汉字
unword=urllib.parse.unquote(word)
print(unword)
resp=urllib.request.urlopen(url+"?word="+word)
data=resp.read()
html=data.decode()
print(html)
使用requests进行GET访问
import flask
app=flask.Flask("web")
@app.route("/")
def getM():#province=flask.request.args.get("province") if "province" in flask.request.args else ""#city=flask.request.args.get("city") if "city" in flask.request.args else ""#若没有值则返回赋值为空province=flask.request.values.get("province","")city=flask.request.values.get("city","")return province+","+city
app.debug=True
app.run()----------------------------------------------------------
#import urllib.request
import requests
url="http://127.0.0.1:5000"
try:resp=requests.get(url,params={"province":"广东","city":"深圳"})#打印返回的二进制print(resp.content)#打印返回的文本print(resp.text)
except Exception as err:print(err)
1.4POST方法访问网站
POST基本使用方法
格式:名称1+值1&名称2=值2&名称3=值3
必须将其使用.encode()转换成二进制数据
import flask
app=flask.Flask("web")
#不写methods则默认为GET方法访问,可以同时允许两种方法访问
#methods=["GET","POST"]
@app.route("/",methods=["POST"])
#访问结果与GET方法完全一致,但是原理已经不一样了
def index():try:#province=flask.request.form.get("province") if "province" in flask.request.form else ""#city=flask.request.form.get("city") if "city" in flask.request.form else ""province=flask.request.values.get("province","")city=flask.request.values.get("city","")return province+","+cityexcept Exception as err:return str(err)
if __name__=="__main__":app.debug=Trueapp.run()--------------------------------------------------------------------
import urllib.parse,urllib.request
url="http://127.0.0.1:5000"
try:province=urllib.parse.quote("广东")city=urllib.parse.quote("深圳")data="province="+province+"&city="+city#转换成二进制数据data=data.encode()html=urllib.request.urlopen(url,data=data)html=html.read()html=html.decode()print(html)
except Exception as err:print(err)
允许get和post同时访问同一个路由
import flask
app=flask.Flask("web")
#不写methods则默认为GET方法访问,可以同时允许两种方法访问
#methods=["GET","POST"]
@app.route("/",methods=["GET","POST"])
#访问结果与GET方法完全一致,但是原理已经不一样了
def index():try:#province=flask.request.args.get("province") if "province" in flask.request.form else ""#city=flask.request.args.get("city") if "city" in flask.request.form else ""#note = flask.request.form.get("note") if "note" in flask.request.form else ""province=flask.request.values.get("province","")city=flask.request.values.get("city","")note=flask.request.values.get("note","")return province+","+city+"\n"+noteexcept Exception as err:return str(err)
if __name__=="__main__":app.debug=Trueapp.run()-----------------------------------------------------------------------
import urllib.parse,urllib.request
url="http://127.0.0.1:5000"
note="深圳依山傍海,气候宜人"
try:province=urllib.parse.quote("广东")city=urllib.parse.quote("深圳")note="note="+urllib.parse.quote(note)param="?province="+province+"&city="+cityhtml=urllib.request.urlopen(url+param,data=note.encode())html=html.read()html=html.decode()print(html)
except Exception as err:print(err)
将翻译改成POST方法
import flask
app=flask.Flask("web")
@app.route("/",methods=["GET","POST"])
def index():dict={"苹果":"apple","桃子":"peach","梨子":"pear"}word=flask.request.values.get("word","")s=""if word in dict.keys():s=dict[word]elif word:s="对不起,字典里面没有"return s
app.debug=True
app.run()-------------------------------------------
import urllib.request
import urllib.parse
url="http://127.0.0.1:5000"
word=input("请输入中文:")
#不能直接向浏览器发送中文
#quote将中文转换成十六进制编码
word="word="+urllib.parse.quote(word)
print(word)
#unquote将十六进制编码转换成汉字
unword=urllib.parse.unquote(word)
print(unword)
resp=urllib.request.urlopen(url,data=word.encode())
data=resp.read()
html=data.decode()
print(html)
Form表单中的POST,提交机密数据
<form action="" method="post">用户:<input type="text" name="user"><br>密码:<input type="password" name="pwd"><br><input type="submit" value="Login">
</form>
<div>{{msg}}</div>
--------------------------------------------------
import flask
app=flask.Flask("web")
@app.route("/",methods=["GET","POST"])
def index():msg=""user=flask.request.values.get("user","")pwd=flask.request.values.get("pwd","")if user=="xxx" and pwd=="123":msg="登陆成功"elif user or pwd:msg="登陆失败"return flask.render_template("login.html",msg=msg)
app.debug=True
app.run()
requests的POST方法
import flask
app=flask.Flask("web")
@app.route("/",methods=["GET","POST"])
def index():try:method=flask.request.methodprovince=flask.request.values.get("province","")city=flask.request.values.get("city","")return method+","+province+","+cityexcept Exception as err:return str(err)
app.debug=True
app.run()
---------------------------------------------
#import urllib.request
import requests
url="http://127.0.0.1:5000"
try:resp=requests.post(url,data={"province":"广东","city":"深圳"})#打印返回的二进制print(resp.content)#打印返回的文本print(resp.text)
except Exception as err:print(err)
1.5Web在下载文件
import flask
import os
app=flask.Flask("web")
@app.route("/")
def index():if "fileName" not in flask.request.values:return "图像.jpg"else:data=b""try:fileName = flask.request.values.get("fileName")if fileName!="" and os.path.exists(fileName):fobj=open(fileName,'rb')data=fobj.read()fobj.close()except Exception as err:data=str(err).encode()return data
app.debug=True
app.run()
---------------------------------------------
import urllib.parse
import urllib.request
#urlretrieve()直接将远程数据下载到本地
#urllib.request.urlretrieve(url,localFile)
url="http://127.0.0.1:5000"
try:html=urllib.request.urlopen(url)html=html.read()fileName=html.decode()print("准备下载:"+fileName)#data=urllib.request.urlopen(url+"?fileName="+urllib.parse.quote(fileName))#data=data.read()#fobj=open("download"+fileName,"wb")#fobj.write(data)#fobj.close()urllib.request.urlretrieve(url+"?fileName="+urllib.parse.quote(fileName),"download"+fileName)#print("下载完毕:",len(data),"字节")print("下载完毕")
except Exception as err:print(err)
静态文件夹文件下载
import urllib.parse
import urllib.request
url="http://127.0.0.1:5000/WebOfFlask/html/images/erha.jpg"
try:resp=urllib.request.urlopen(url)data=resp.read()fobj=open("download img.jpg","wb")fobj.write(data)fobj.close()print("下载完毕",len(data),'bytes')
except Exception as err:print(err)
1.6Web上传文件
往往先创建一个header,告诉服务器当前传递的一个数据是二进制的数据流
#urllib.request.Request(purl,data,headers)
headers={'content-type':'application/octet-stream'}
req=urllib.request.Request(url,data,headers)
import flask
app=flask.Flask(__name__)
@app.route("/upload",methods=["POST"])
def uploadFile():msg=""try:if "fileName" in flask.request.values:fileName=flask.request.values.get("fileName")#获取二进制的数据data=flask.request.get_data()fobj=open("upload"+fileName,"wb")fobj.write(data)fobj.close()msg="OK"else:msg="没有按要求上传文件"except Exception as err:print(err)msg=str(err)return msg
if __name__=="__main__":app.debug=Trueapp.run()
------------------------------------------------------
import urllib.request
import urllib.parse
import os
url="http://127.0.0.1:5000/upload"
fileName=input("Enter the file:")
if os.path.exists(fileName):fobj=open(fileName,"rb")data=fobj.read()fobj.close()#包含路径的话截取最后一个反斜杠直到最后当作文件名称p=fileName.rfind("\\")fileName=fileName[p+1:]print("准备上传:"+fileName)#通过headers告诉服务器上传的是一个二进制文件流headers={'content-type':'application/octet-stream'}purl=url+"?fileName="+urllib.parse.quote(fileName)#创建一个request对象req=urllib.request.Request(purl,data,headers)#urlopen可以接受一个url或一个request对象msg=urllib.request.urlopen(req)msg=msg.read().decode()if msg=="OK":print("成功上传:",len(data),"字节")else:print(msg)
else:print("文件不存在!")
使用base64字符串上传文件
将文件以文件名,文件二进制流方式传输,需要转换成json字符串,二进制流不能直接转换成json,需要通过base64进行数据格式的转换
import flask
import base64
import io
import json
app=flask.Flask("web")
@app.route("/",methods=["GET","POST"])
def index():msg=""try:data=flask.request.get_data()#将接收的二进制数据decode,转成一个字符串,用json的形式装载进来即将json数据还原为字典data=json.loads(data.decode())#字典中的body就是文件字符串body=data["body"]outstream=io.BytesIO()#将body中的base64的字符串转换为二进制字符串base64.decode(io.BytesIO(body.encode()),outstream)#此时body就是二进制数据流body=outstream.getvalue()#打印出现有的文件名和长度print(data["fileName"],len(body))fobj=open("upload"+data['fileName'],"wb")fobj.write(body)fobj.close()msg="服务器接收"+str(len(body))+"字节"except Exception as err:print(err)msg=str(err)return msg
if __name__=="__main__":app.debug=Trueapp.run()
-----------------------------------------------------
"""
此方式实际上传的是一个字典的json数据,这个字典有两个值,一个是文件名,一个是body,body是一个base64的很长的字符串
"""
import base64
import urllib.request
import io
import json
url="http://127.0.0.1:5000"
try:fobj=open("图像.jpg",'rb')data=fobj.read()fobj.close()print("客户端上传",len(data),"字节")#输入流,输出流instream=io.BytesIO(data)outstream=io.BytesIO()#使用base64将输入流转换成输出流,就会变成一个base64字符串的输出流base64.encode(instream,outstream)#将输出流的值变成字符串,即整个图像变成字符串body=outstream.getvalue().decode()#将这个字符串做成一个字典对象data={'fileName':'图像.jpg','body':body}#将这个字典对象做成一个json字符串,将json字符串抓换成二进制数据data=json.dumps(data).encode()#告诉服务器上传的是一个数据流headers={'content-type':'application/octet-stream'}req=urllib.request.Request(url,data,headers=headers)resp=urllib.request.urlopen(req)s=resp.read().decode()print(s)
except Exception as err:print(err)
1.7正则表达式
re模块:e用来引导所需要的正则表达式字符串
各个字符代表的含义
import re
#查找来按需的数字
reg=r"\d+"
m=re.search(reg,"abc123cd")
print(m)
#<re.Match object; span=(3, 6), match='123'>
#出现的位置起始下标是3,结束下表是6
#若匹配不到则返回None#字符串"\d"匹配0-9之间的一个数值
reg=r"\d"
m=re.search(reg,"abc123cd")
print(m)
#<re.Match object; span=(3, 4), match='1'>
#字符"+"重复前一个匹配字符一次或多次
reg=r"b\d+"
#匹配起始字符是b后面连续出现多个数字
m=re.search(reg,"a12b123c")
print(m)
#<re.Match object; span=(3, 7), match='b123'>#字符"*"重复前一个匹配字符0次或多次
reg=r"ab+"
m=re.search(reg,"acabc")
print(m)
#<re.Match object; span=(2, 4), match='ab'>
reg=r"ab*"
m=re.search(reg,"acabc")
print(m)
#<re.Match object; span=(0, 1), match='a'>#字符"?"重复前一个匹配字符零次或一次
reg=r"ab?"
m=re.search(reg,"abbcabc")
print(m)
#<re.Match object; span=(0, 2), match='ab'>#字符"."代表任何一个字符,并未声明不代表字符"\n"
s="xaxby"
m=re.search(r"a.b",s)
print(m)
#<re.Match object; span=(1, 4), match='axb'>#"|"代表把左右分成两部分,即要匹配的字符串要么符合|左边的,要么符合右边的,其中一个满足即可
s="xaabababy"
m=re.search(r"ab|ba",s)
print(m)
#<re.Match object; span=(2, 4), match='ab'>#特殊字符使用反斜线"\"引导如"\r"、"\n"、"\t"、"\\"分别代表回车、换行、制表符号和反斜线自己本身
reg=r"a\nb?"
s="ca\nbcabc"
m=re.search(reg,s)
print(m)
#<re.Match object; span=(1, 4), match='a\nb'>#字符"\b"表示单词词尾,包含各种空白字符或字符串结尾
reg=r"car\b"
m=re.search(reg,"The car is black")
print(m)
#<re.Match object; span=(4, 7), match='car'>#"[]"中的字符是任选择一个
#SACII中连续的一组可用"-"符号连接
#如[0-9]即匹配0-9中的任意一个数字
#[A-Z]即匹配A-Z其中一个大写字符
#[0-9A-Z]即匹配0-9的其中一个数字或者A-Z的其中一个大写字符reg=r"x[0-9]y"
m=re.search(reg,"xyx2y")
print(m)
#<re.Match object; span=(2, 5), match='x2y'>#"^"出现在[]第一个字符位置,代表取反,即对后面的含义进行否定
#如[^ab0-9]表示不是a、b,也不是0-9的数字
reg=r"x[^ab0-9]y"
m=re.search(reg,"xayx2yxcy")
print(m)
#<re.Match object; span=(6, 9), match='xcy'>#"\s"匹配任何空白字符,等价"[\r\n\x20\t\f\v]"
s="1a ba\tbxy"
m=re.search(r"a\sb",s)
print(m)
#<re.Match object; span=(1, 4), match='a b'>#"\w"匹配包括下划线子内单词字符,等价于"[a-zA-Z0-9_]",即字母数字下划线
reg=r"\w+"
m=re.search(reg,"Python is easy")
print(m)
#<re.Match object; span=(0, 6), match='Python'>#"^"匹配字符串开头位置
reg=r"^ab"
m=re.search(reg,"cabcab")
print(m)
#None#"$"符号匹配字符串结尾位置
#匹配ab,同时ab要是字符产的结尾
reg=r"ab$"
m=re.search(reg,"abcab")
print(m)
#<re.Match object; span=(3, 5), match='ab'>#使用(...)把(...)看成整体
#经常与"+"、"*"、"?"连续使用,对(...)部分进行重复
reg=r"(ab)+"
m=re.search(reg,"ababcab")
print(m)
#<re.Match object; span=(0, 4), match='abab'>
re.search()方法
import re
#查找匹配字符串
# m=re.search(reg,s)
# m.start()返回字符串开始的位置
# m.end()返回字符串结束的位置
# 若没匹配上则返回None
s="I am testing search function"
reg=r"[A-Za-z]+\b"
m=re.search(reg,s)
while m!=None:start=m.start()end=m.end()print(s[start:end])s=s[end:]m=re.search(reg,s)
使用正则表达式爬取图像文件
server
import flask
##初始化一个Flask对象,参数__name__是程序的名称
#也可以给这个app起个别的名字app=flask.Flask("web")
#指定默认静态文件夹
app=flask.Flask(__name__,static_folder="html")
@app.route("/plates")
def plates():return flask.render_template("index.html")
if __name__=="__main__":# 打开服务器的调试模式app.debug=Trueapp.run(port=5000)
index
<h1>Image</h1>
<img src='html/images/erha.jpg' width='200'>
<img src='html/images/erha2.jpg' width='200'>
<div>It is very easy to make a web application</div>
spider
import re
import urllib.request
def download(src):try:resp=urllib.request.urlopen(src)data=resp.read()p=src.rfind("/")fileName=src[p+1:]fobj=open('downloadf\\'+fileName,'wb')fobj.write(data)fobj.close()print("downloaded",fileName)except Exception as err:print(err)
url="http://127.0.0.1:5000/plates"
try:resp=urllib.request.urlopen(url)data=resp.read()html=data.decode()reg=r"<img.+src="m=re.search(reg,html)while m:a=m.end()s=html[a:]#print(s)n=re.search(r"\'.+g\'",s)b=n.end()src=s[1:b-1]src=urllib.request.urljoin(url,src)print(src)download(src)#开始查找第二个字符html=s[n.end():]m=re.search(reg,html)
except Exception as err:print(err)
改写正则表达式,修复空格问题,单双引号问题
spider
import re
import urllib.request
def download(src):try:resp=urllib.request.urlopen(src)data=resp.read()p=src.rfind("/")fileName=src[p+1:]fobj=open('downloadf\\'+fileName,'wb')fobj.write(data)fobj.close()print("downloaded",fileName)except Exception as err:print(err)url="http://127.0.0.1:5000/plates"
try:resp=urllib.request.urlopen(url)data=resp.read()html=data.decode()reg=r"<img.+src\s*=\s*"m=re.search(reg,html)print(m)while m:a=m.end()s=html[a:]#这里------------------------------------------------n=re.search(r"[\',\"].+g[\',\"]",s)b=n.end()src=s[1:b-1]src=urllib.request.urljoin(url,src)print(src) download(src)#开始查找第二个字符html=s[n.end():]m=re.search(reg,html)
except Exception as err:print(err)
index
<h1>Image</h1>
<img src = 'html/images/erha.jpg' width='200'>
<img src="html/images/erha2.jpg" width='200'>
<div>It is very easy to make a web application</div>
下载chinadaily网站中的图片

使用正则表达式爬取学生信息
students.txt
No,Name,Gender,Age
1001,张三,男,20
1002,李四,女,19
1003,王五,男,21
server.py
import flask
import os
app=flask.Flask(__name__)
@app.route("/")
def show():if os.path.exists("students.txt"):st="<h3>学生信息表</h3>"st=st+"<table border='1' width='300'>"fobj=open("students.txt","rt",encoding="utf-8")while True:#读取一行,去除行尾部"\n"换行符s=fobj.readline().strip("\n")print(s)#如果读到文件尾部就退出if s=="":break#按逗号拆分开s=s.split(",")st=st+"<tr>"#把各个数据组织在<td>...</td>的单元中for i in range(len(s)):st=st+"<td>"+s[i]+"</td>"#完成一行st=st+"</tr>"fobj.close()st=st+"</table>"return st
if __name__=="__main__":app.debug=Trueapp.run()
client.py
import urllib.request
import re
try:resp=urllib.request.urlopen("http://127.0.0.1:5000")data=resp.read()html=data.decode()print(html)#找出这一行的开始与结束,若有开始和结束 则进入循环m=re.search(r"<tr>",html)n=re.search(r"</tr>",html)while m!=None and n!=None:#去掉tr标签取出中间td部分#<td>No</td><td>Name</td><td>Gender</td><td>Age</td>row=html[m.end():n.start()]print(row)#找这一行当中的第一个td标签的开始与结束位置a=re.search(r"<td>",row)b=re.search(r"</td>",row)#找出这一对td标签的开始与结束,若有则进入循环取出td中的内容while a!=None and b!=None:s=row[a.end():b.start()]#将此单元格的数据进行是打印输出print(s,end=" ")#将行tr进行截取,用于进入下一次循环取出td标签row=row[b.end():]a=re.search(r"<td>",row)b=re.search(r"</td>",row)#将一个tr标签中的td取完以后进入下一行(下一个tr),并输出一个换行print()#将行html进行截取,用于进入下一次循环取出tr标签html=html[n.end():]m=re.search(r"<tr>",html)n=re.search(r"</tr>",html)
except Exception as err:print(err)
常用的正则表达式
#变量
reg=r"[a-zA-Z]\w+"
#手机号:13、15、17、18开头
reg=r"((13[0-9])|(15[0-9])|(17[0-9])|(18[0-9]))\d{8}"
#匹配18位身份证号码
reg=r"\d{17}[0-9Xx]"
#匹配IP地址
reg=r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}"
#匹配YYYY-mm-dd的日期
reg=r"(\d{2}|\d{4})-\d{1,2}-\d{1,2}"
#匹配浮点数
reg=r"-?\d*\.\d*"
#匹配Email地址
reg=r"^[A-Za-z0-9_-]+@[A-Za-z0-9_-]+(\.[A-Za-z0-9_-]+)+$"
1.8爬取外汇网站的数据
本次要爬取的网站:fx.cmbchina.com/hq
首先看一下此网站的关键代码
<div id="realRateInfo"><table cellpadding="0" cellspacing="1" width="740" align="center" class="data"><tr><td class="head fontbold" width="70">交易币</td><td class="head" width="65">交易币单位</td><td class="head fontbold" width="55">基本币</td><td class="head" width="65">现汇卖出价</td><td class="head" width="65">现钞卖出价</td><td class="head" width="65">现汇买入价</td><td class="head" width="65">现钞买入价</td><td class="head" width="65">时间</td><td class="head">汇率走势图</td></tr><tr><td class="fontbold">港币</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">89.94</td><td class="numberright">89.94</td><td class="numberright">89.58</td><td class="numberright">88.95</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('港币');">查看历史>></a></td></tr><tr><td class="fontbold">新西兰元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">442.00</td><td class="numberright">442.00</td><td class="numberright">438.48</td><td class="numberright">424.61</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('新西兰元');">查看历史>></a></td></tr><tr><td class="fontbold">澳大利亚元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">468.49</td><td class="numberright">468.49</td><td class="numberright">464.75</td><td class="numberright">450.05</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('澳大利亚元');">查看历史>></a></td></tr><tr><td class="fontbold">美元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">704.04</td><td class="numberright">704.04</td><td class="numberright">699.58</td><td class="numberright">693.86</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('美元');">查看历史>></a></td></tr><tr><td class="fontbold">欧元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">761.23</td><td class="numberright">761.23</td><td class="numberright">755.17</td><td class="numberright">731.28</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('欧元');">查看历史>></a></td></tr><tr><td class="fontbold">加拿大元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">521.81</td><td class="numberright">521.81</td><td class="numberright">517.65</td><td class="numberright">501.28</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('加拿大元');">查看历史>></a></td></tr><tr><td class="fontbold">英镑</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">876.82</td><td class="numberright">876.82</td><td class="numberright">869.84</td><td class="numberright">842.33</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('英镑');">查看历史>></a></td></tr><tr><td class="fontbold">日元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">5.1061</td><td class="numberright">5.1061</td><td class="numberright">5.0655</td><td class="numberright">4.9053</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('日元');">查看历史>></a></td></tr><tr><td class="fontbold">新加坡元</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">523.52</td><td class="numberright">523.52</td><td class="numberright">519.34</td><td class="numberright">502.92</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('新加坡元');">查看历史>></a></td></tr><tr><td class="fontbold">瑞士法郎</td><td align="center">100</td><td align="center" class="fontbold">人民币</td><td class="numberright">783.09</td><td class="numberright">783.09</td><td class="numberright">776.85</td><td class="numberright">752.28</td><td align="center">9:10:04</td><td align="center"><a href="javascript:link2History('瑞士法郎');">查看历史>></a></td></tr></table><span class="tip">以上资料仅供参考,以办理业务时的实时汇率为准。</span>
</div>
分析
- 获取该网站的HTML字符串
- 用正则表达式匹配 和,取出他们的中间部分的字符串HTML
- 匹配与,取出他们中间的字符串i并命名为tds
- 再到tds中去匹配与,取出各个…中的数据,并将数据存储到数据库,数据包含在HTML代码的…中,为了爬取各个…中的数据,我们设计一个匹配函数match()
设计存储数据库
| 字段名称 | 类型 | 说明 |
|---|---|---|
| Currency | varchar(256) | 外汇名称(关键字) |
| TSP | float | 现汇卖出价 |
| CSP | float | 现钞卖出价 |
| TBP | float | 现汇买入价 |
| CBP | float | 现钞买入价 |
| Time | varchar(256) | 时间 |
爬虫程序
import urllib.request
import re
import sqlite3
class MySpider:def openDB(self):#初始化数据库,船建数据库rates.db与一张空表ratesself.con=sqlite3.connect("rates.db")self.cursor=self.con.cursor()try:self.cursor.execute("drop table rates")except Exception as err:passsql="create table rates(Currency varchar(256) primary key,TSP float,CSP float,TBP float,CBP float,Time varchar(256))"self.cursor.execute(sql)def closeDB(self):#并关闭数据库self.con.commit()self.con.close()def insertDB(self,Currency,TSP,CSP,TBP,CBP,Time):#记录插入数据库try:sql="insert into rates(Currency,TSP,CSP,TBP,CBP,Time) values(?,?,?,?,?,?)"self.cursor.execute(sql,[Currency,TSP,CSP,TBP,CBP,Time])except Exception as err:print(err)def show(self):#显示函数self.cursor.execute("select Currency,TSP,CSP,TBP,CBP,Time from rates")rows=self.cursor.fetchall()#规定显示格式print("%-18s%-12s%-12s%-12s%-12s%-12s"%("Currency","TSP","CSP","TBP","TBP","Time"))for row in rows:print("%-18s%-12s%-12s%-12s%-12s%-12s"%(row[0],row[1],row[2],row[3],row[4],row[5]))def match(secf,t,s):#匹配函数,主要匹配标签的位置m=re.search(r"<"+t,s)if m:a=m.start()m=re.search(r">",s[a:])if m:b=a+m.end()return {"start":a,"end":b}return Nonedef spider(self,url):#爬虫函数try:resp=urllib.request.urlopen(url)data=resp.read()html=data.decode()m=re.search(r'<div id="realRateInfo">',html)html=html[m.end():]m=re.search(r"</div>",html)#取出<div id="realRateInfo">...</div>部分html=html[:m.start()]i=0while True:p=self.match("tr",html)q=self.match("/tr",html)if p and q:i+=1a=p["end"]b=q["start"]tds=html[a:b]row=[]count=0while True:m=self.match("td",tds)n=self.match("/td",tds)if m and n:u=m["end"]v=n["start"]count+=1if count<=8:row.append(tds[u:v].strip())tds=tds[n["end"]:]else:#匹配不到<td>...</td>,退出内层循环breakif i>=2 and len(row)==8:Currency =row[0]TSP=float(row[3])CSP=float(row[4])TBP=float(row[5])CBP=float(row[6])Time=row[7]self.insertDB(Currency,TSP,CSP,TBP,CBP,Time)html=html[q["end"]:]else:#匹配不到<tr>...</tr>breakexcept Exception as err:print(err)def process(self):#爬取过程self.openDB()self.spider("http://fx.cmbchina.com/hq/")self.show()self.closeDB()
#主程序
spider=MySpider()
spider.process()